论文阅读:《Optimizing Computational Resources for Edge Intelligence Through Model Cascade Strategies》
本文章内容改编自笔者于2024年11月6日、在本学期选修课程《边缘智能前沿与应用》中做的论文汇报。
将本文章上传至博客的目的是测试Hexo对Markdown格式内容的支持程度,利用撰写、上传、校对这篇博文的过程,给后续工作踩坑。
论文信息
汇报所述论文是由西班牙得乌斯托大学和英国剑桥大学的教授,发表在CCF-C类国际学术期刊IOT上的一篇文章。
目录
- 问题背景
- 相关概念(前置知识)
- 模型级联优化算法(Model Cascade Optimization Approach)
- 实验设计与结果分析
- 总结与后续展望
问题背景
边缘计算,作为云端计算的一种替代方案,让数据在更加靠近数据产生的地方进行处理,也为我们提出了新的要求。比如,边缘设备在可用的计算资源等方面是受限的,如何用这些受限的资源去完成复杂的计算任务,是本论文关注的问题。
论文认为,为了减少边缘设备运算的资源花费,可以从降低AI模型的复杂度入手。所以,本文提出了一种简化对边缘监督学习复杂度的方法,在物联网架构中节省资源需求方面具有很大的潜力。
相关概念(前置知识)
在介绍论文方法和实验之前,先对论文中提到的一些相关技术和概念进行阐述,有助于我们更好地理解论文内容。
首先,介绍集成学习。它是机器学习的一个分支,目前集成学习流行的方法有Bagging,Boosting,Stacking,以及本文用到的Cascading。它们都可以用来提升模型在分类任务上的性能。
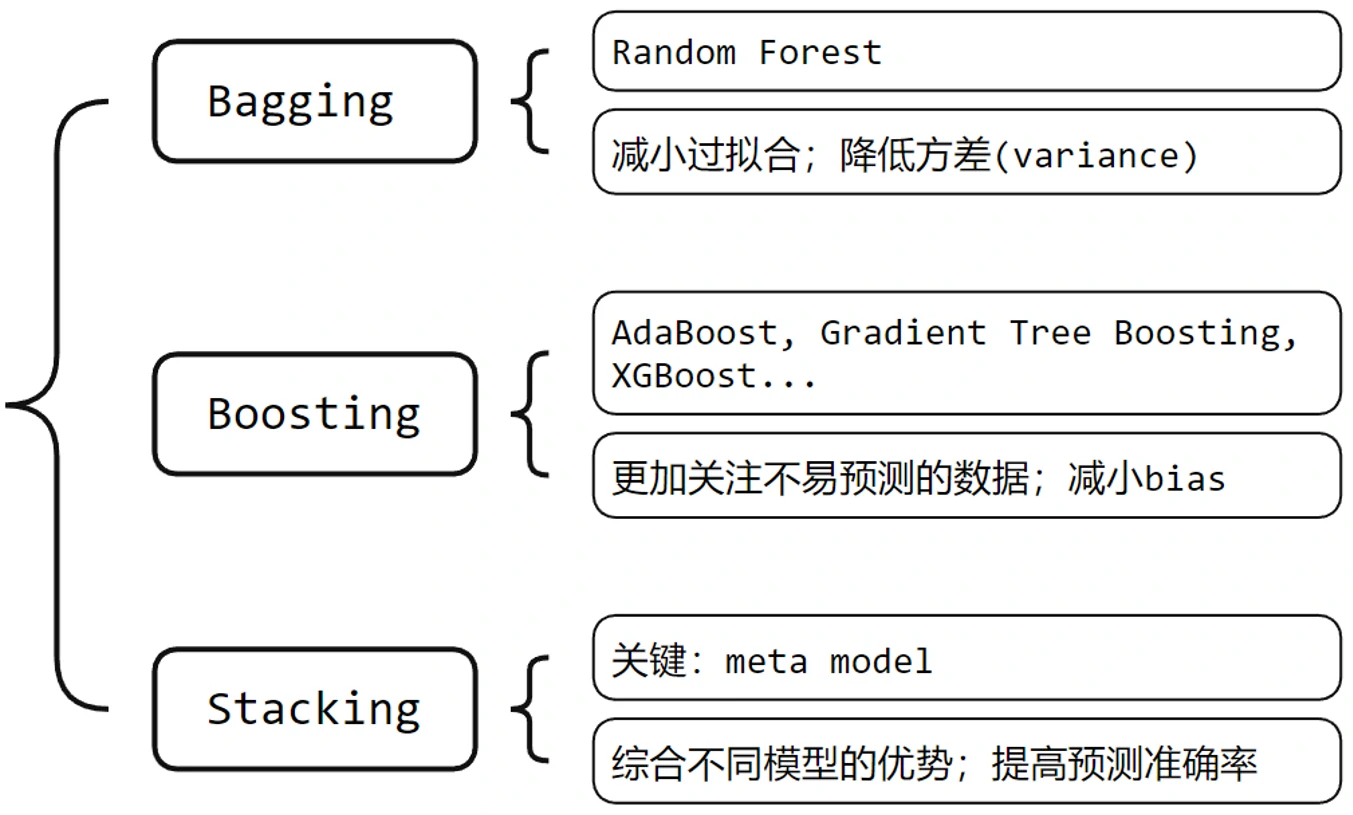
- Bagging全称Boostrap agreggation,它的关键思想是,先把原始数据集通过抽样形成很多小的数据集(叫做boostrap),然后用每一个小数据集去训练一个模型。在给模型做测试的时候,对所有模型的预测结果取平均得到一个最终的预测结果。这种方法的好处是能减少模型的过拟合,并且能减少模型预测的方差。像随机森林里就用到了Bagging有关的思想。
- Boosting是一种序列化的集成方式,在Boosting方法下,我们先训练一个模型,再根据它的错误率去调节训练样本的权重,让后续做训练的模型更加关注那些前面模型难以预测的样本数据。它的好处是能减少模型的bias。像AdaBoost、Gradient Tree Boosting、XGBoost都用到了Boosting的思想。
- Stacking是一种多层次的集成方式,它首先会训练一些采取不同策略的模型,把预测结果作为新的特征来生成一个新的数据集,用这个新数据集去训练一个最终的模型(meta model),这个最终的模型的策略与复杂度可以自行设置。Stacking的优点是,如果meta model选择得好,就能结合多种不同模型的优势,从而提高预测准确率。
然后,因为论文的实验是让模型完成分类任务,所以我们需要简要介绍一些多标签分类中用到的一些概念和指标。
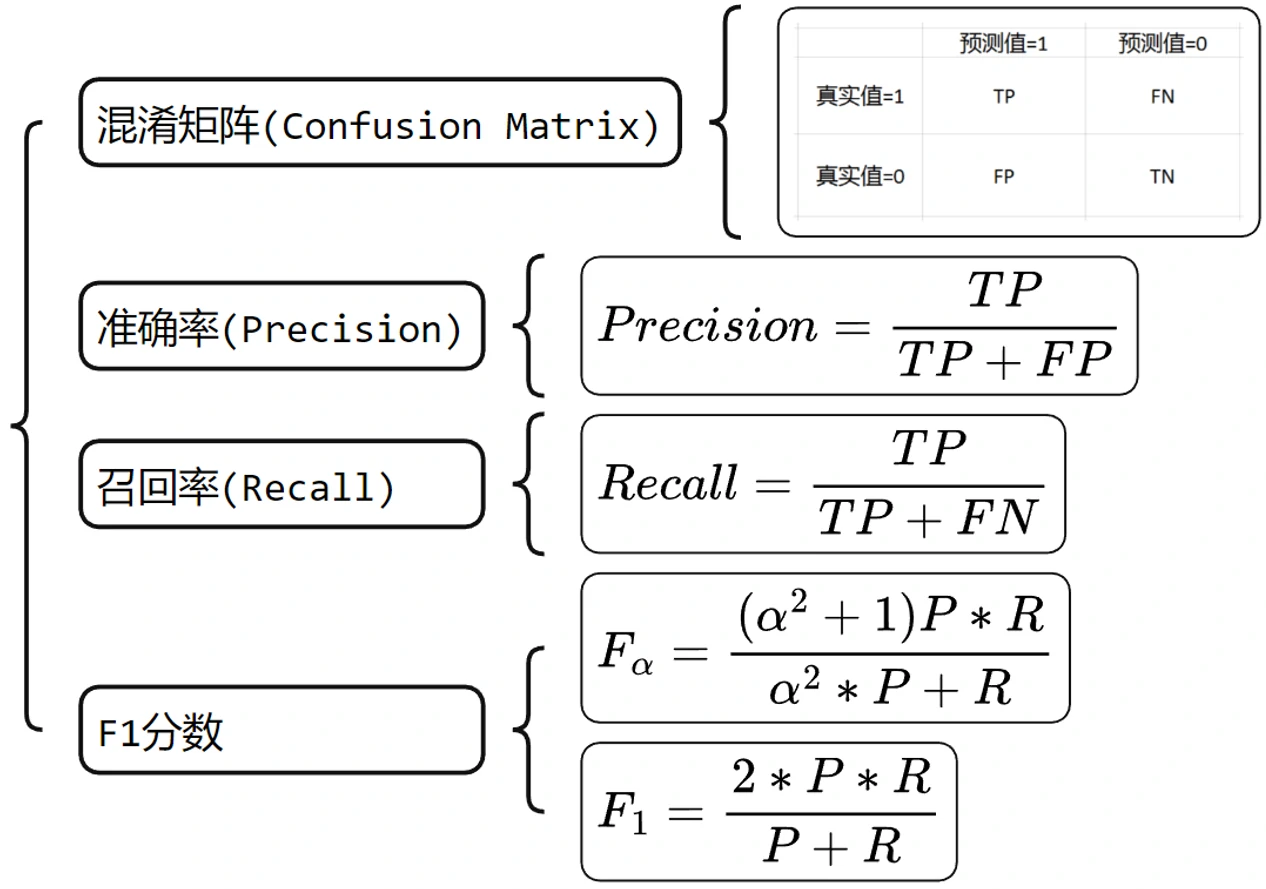
对于每一个特征,根据样本的标签类别的正负以及模型预测结果的正负,可以分为TP、FP、FN、TN四个类别,T和F代表模型预测是正确还是错误,P和N是模型预测认为这个结果是正例还是负例。我们用四个类别就可以做出一个混淆矩阵。用这四个类别下的样本数量可以计算出一些指标,比如模型预测的准确率是模型预测结果是正例的样本里,实际上确实是正例的样本占的比例,模型预测的召回率是样本中所有实际上是正例的样本里,模型预测为正例的样本占的比例。综合准确率和召回率可以得到一个F分数,其中
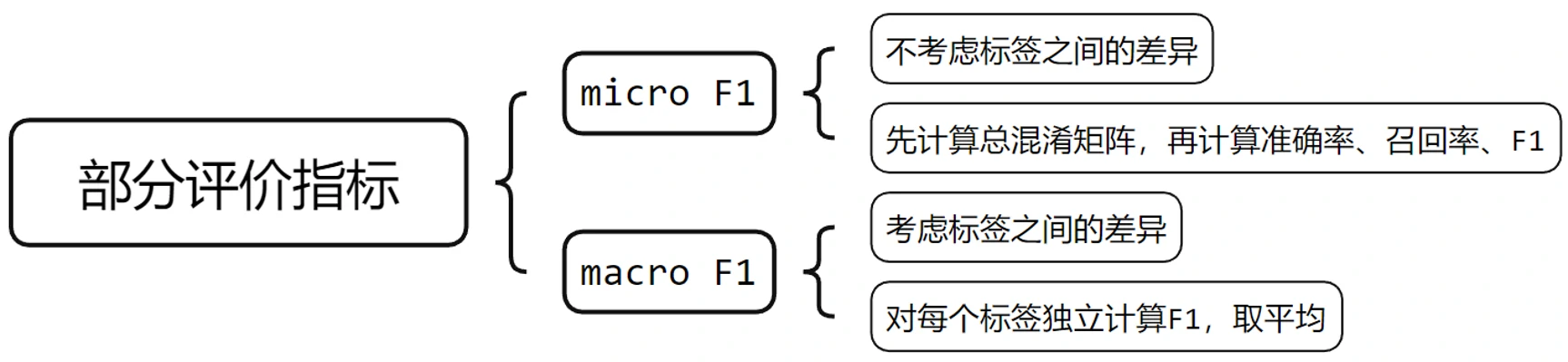
在多标签分类任务下,模型对每种标签的预测结果都可以写出一个混淆矩阵,那么我们就有两种不同的方法去综合这些标签的预测结果来得到F1分数,比如micro F1就是不考虑不同标签之间的差异,先把所有混淆矩阵加起来,再去算一个总的准确率、召回率和F1分数;macro F1考虑了不同标签之间的差异,先对每个标签做混淆矩阵、算F1分数,再取平均值。论文后面会用到这个macro F1分数。
最后我们再简要说一下论文实验中的人类活动识别任务。人类活动识别简称HAR(Human Activity Recognition),指通过分析来自传感器的数据,自动检测并分类个体在特定时间段内所进行的各种活动的技术。HAR是处理传感器采集的各项数据,而不是从监控等图像中识别人体姿态,所以要把HAR和目标检测任务区分开。
图片来源:https://doi.org/10.1016/j.knosys.2021.106970
模型级联优化算法(Model Cascade Optimization Approach)
接下来介绍论文提出的模型级联优化方法。这是一种针对特定受限场景的集成学习方法,旨在通过级联结构提升预测性能并降低计算复杂度。
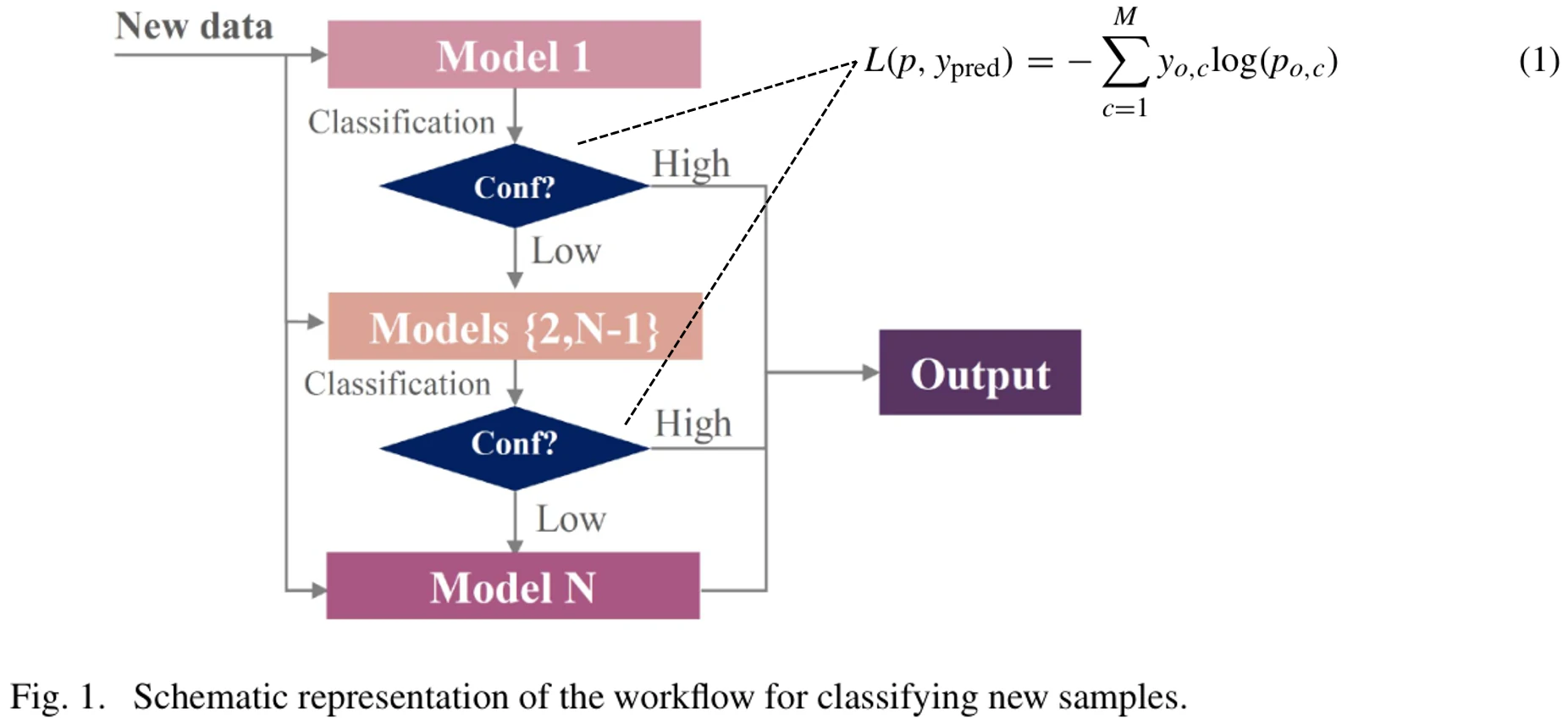
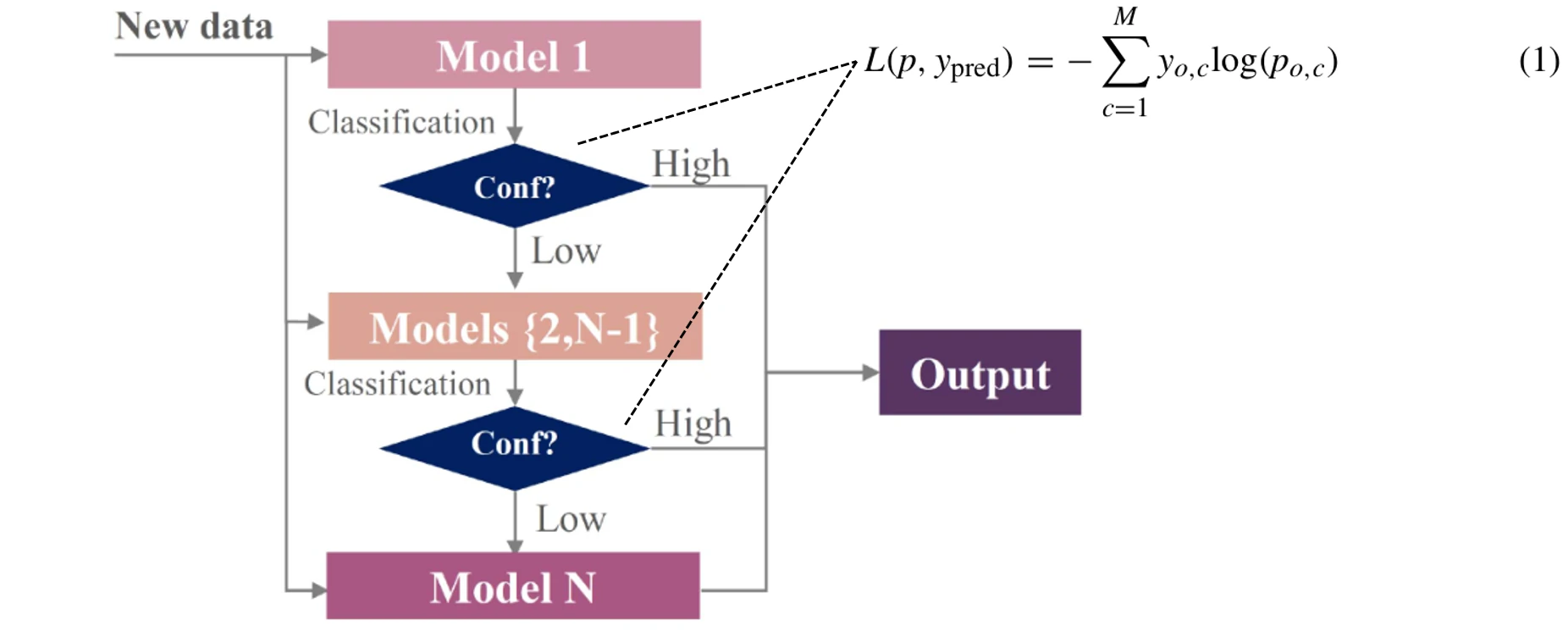
图1展示了论文提出的模型级联方法,它由一系列连续的
样本首先进入最初的模型,得到一个预测结果。如果这个预测结果的置信度高于我们事先预设的阈值
论文给出了预测结果的置信度的计算公式,也就是公式1,它反映了模型输出的预测结果的可靠程度有多少。公式中M指样本标签的种类数量,
公式的主要思想是让样本属于各个种类的概率向量和被预测样本的label做对比,计算各个类别的log loss,即使样本真正属于的种类是未知的,我们也能用这个公式去衡量模型分类的可靠性。
这种模型级联的设计,使得前面的简单模型起到过滤样本的作用,减少了如果一个样本在前面简单的模型里就得到了可靠的分类预测结果,那么它就不会进入后面更复杂的模型,设备在计算上消耗的资源就降低了。
(论文还提到一些优化这个结构的方法,比如,在信号数据处理和特征提取阶段进行了优化。一个样本也许能提取出很多特征,但是这些特征不一定全部参与到计算,在前面简单的模型里,参与计算的特征数量更少,其他特征在需要时会在后面更加复杂的模型中计算。这种设计可能使得新样本只需使用最初、最简单的分类器进行标签预测。)
在具体实现上,论文根据模型训练的方法,提出了三种不同的实现这个模型级联的方式,分别是并行实现、顺序实现和混合实现。这三种实现方式的区别在于训练每一层模型用的数据不一样。
首先是并行实现。在并行实现里每一层模型在输入和训练方面都是独立的,每一层模型都用数据集中所有可用的数据来作训练。
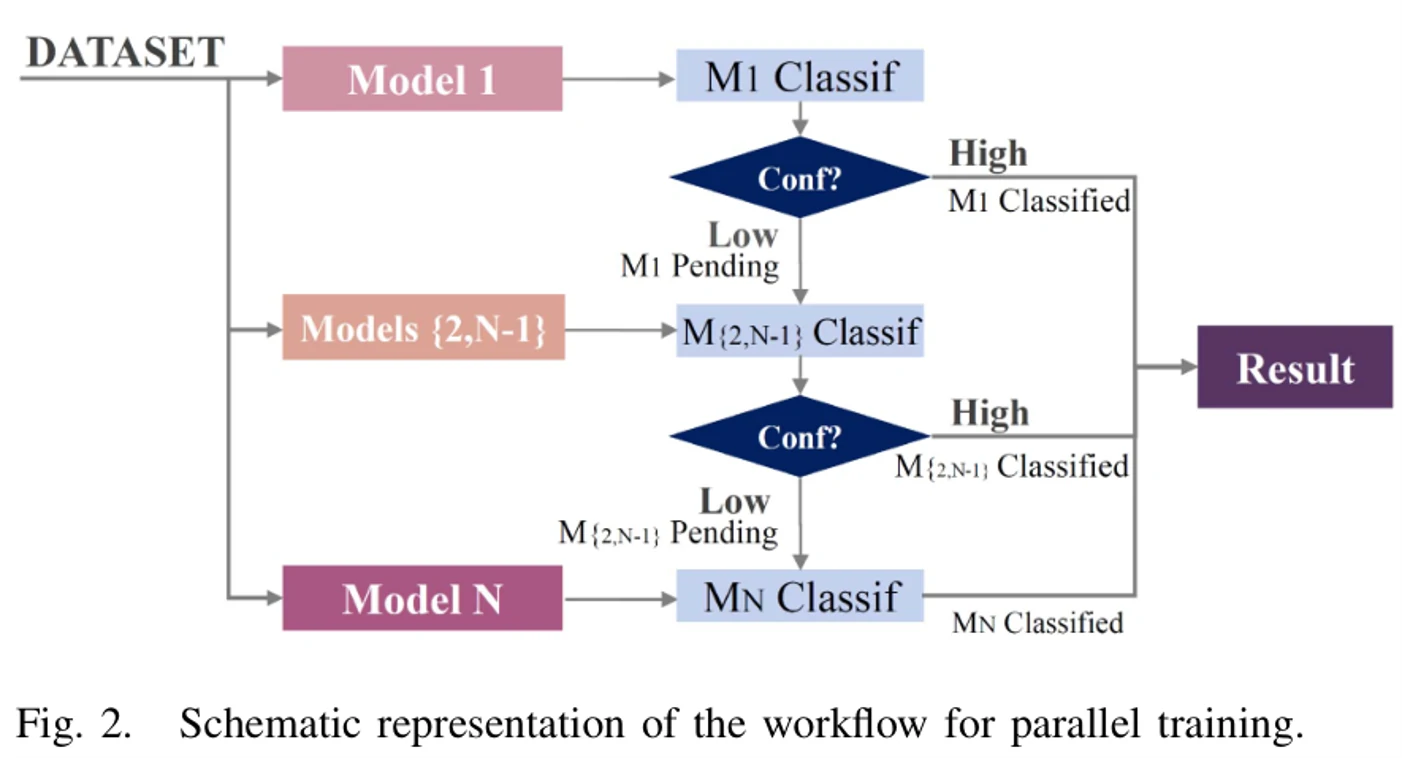
并行实现
再就是顺序实现。在顺序实现里,最初的模型使用整个训练集进行训练,而后续模型则只使用在上一层中置信值不高于阈值
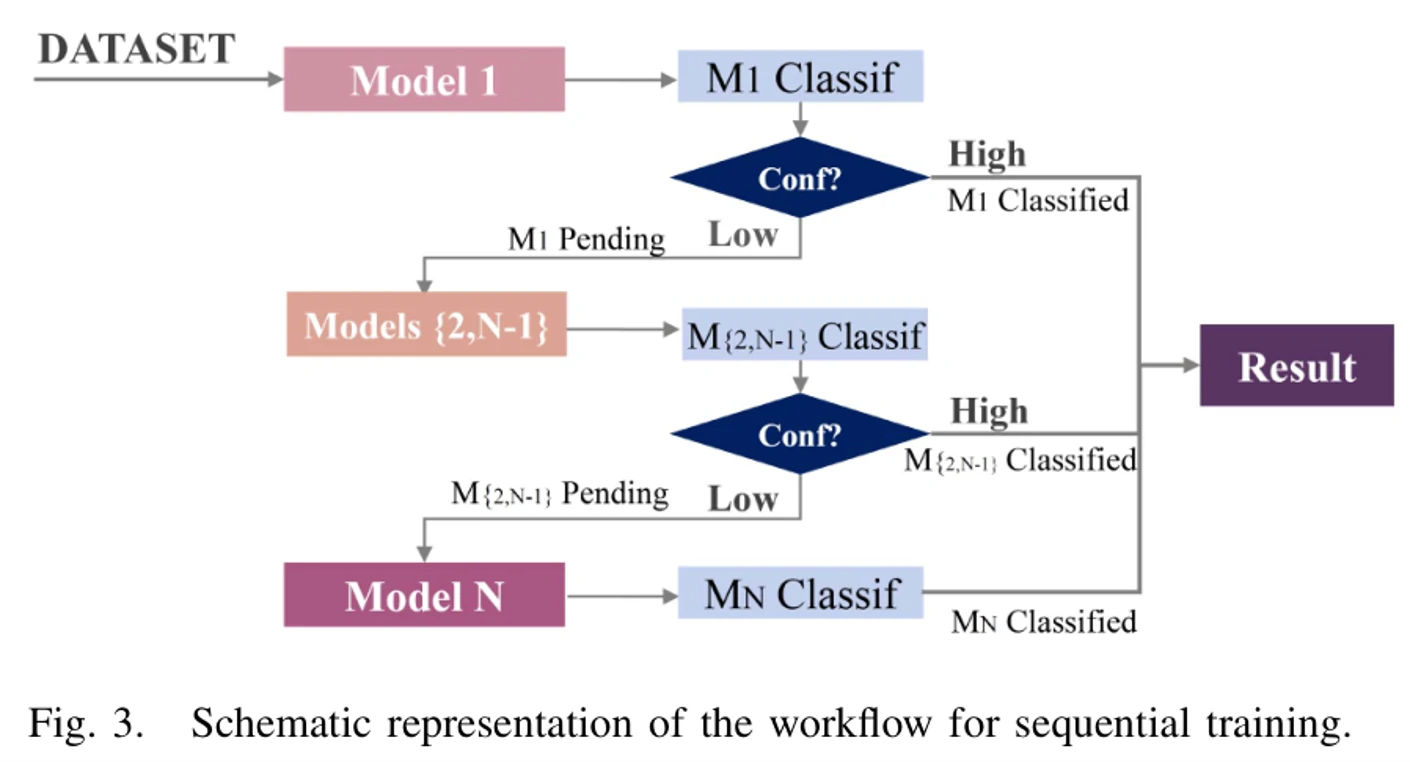
顺序实现
最后是混合实现。在混合实现里,前
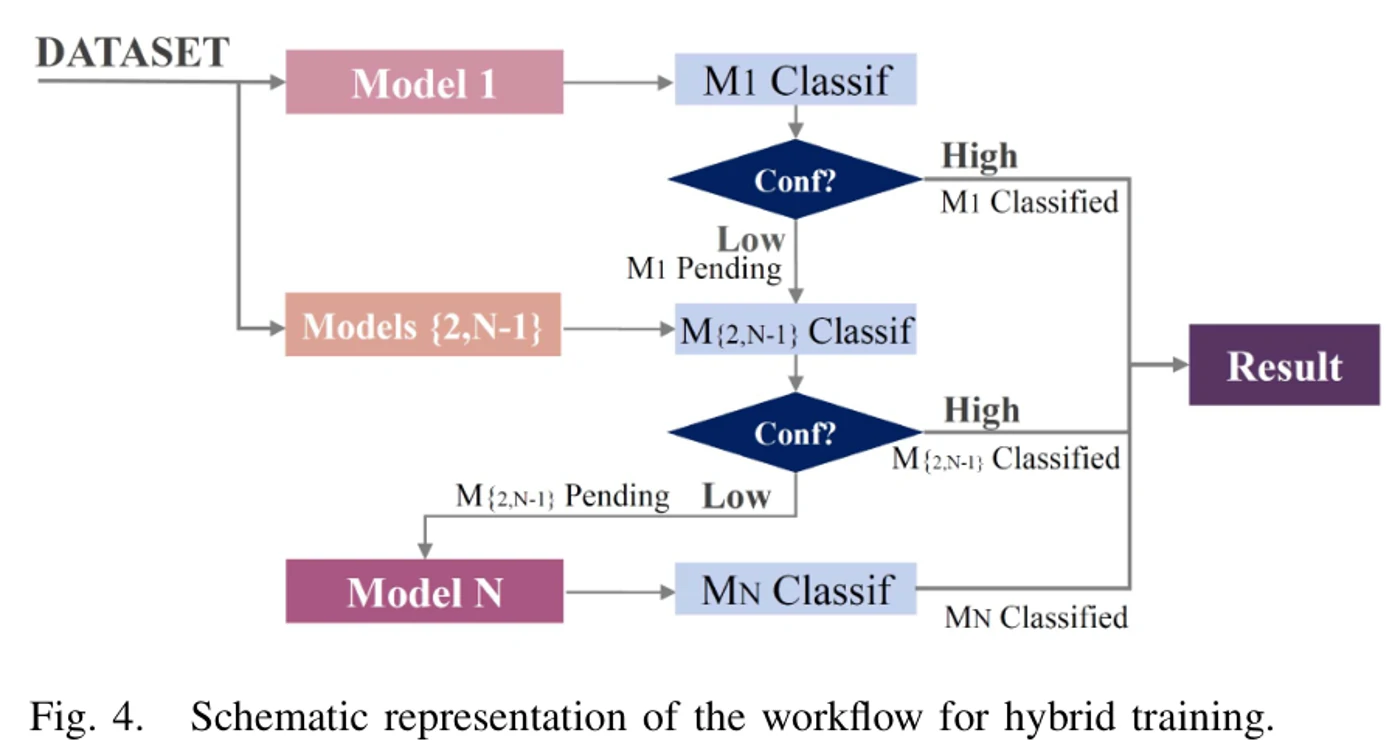
混合实现
实验设计与结果分析
论文的整个实验过程,用简单的话来概括就是,让几种不同的边缘设备搭载不同的模型,在相同的实验条件下进行人类活动识别分类任务,并最终从分类准确性、分类效率、计算消耗三个方面来进行对比,得到实验结果。
实验设计
首先介绍论文实验使用的数据集。论文一共用了五个数据集,其中有四个是公开的数据集,它们包含了用动作传感器收集人类活动识别数据。具体包括:
- ADL数据集,使用腕带式加速度计收集;
- HAR数据集,基于智能手机收集;
- 办公室活动识别数据集;
- 日常与运动活动数据集,仅使用躯干和右臂的传感器。
除了公开数据集,论文团队还创建了一个名为 OHM(Office Hydration Monitoring) 的数据集,用于监控办公室员工的喝水方式。该数据集通过放置在不同容器的加速度计和陀螺仪进行收集,包含1000个实例,涉及10个测试人员和25种不同的交互方式。(为模拟真实场景,志愿者的动作指引较为模糊,且使用自己的喝水容器,传感器位置也不固定,从而营造较大数据方差。
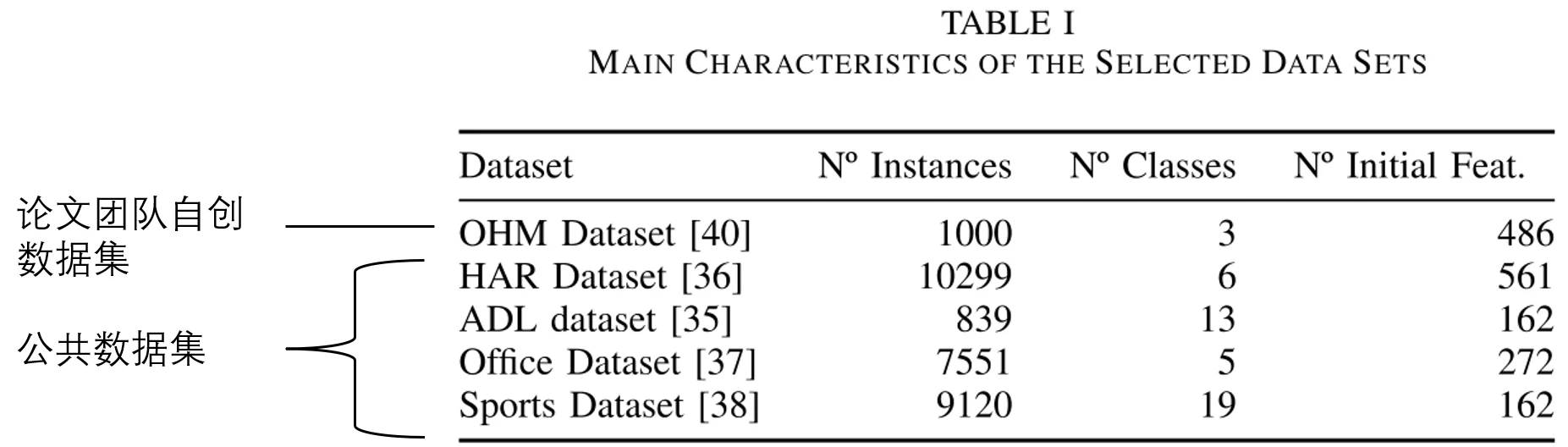
数据集
接下来,论文规定了实验所用的模型的算法。论文团队选用了一系列经典的机器学习分类器,(这些分类器在资源受限的环境下对来自物联网传感器的连续数据序列进行分类时具有较高的效率。)具体包括逻辑回归(LG)、随机森林(RF)、KNN、高斯贝叶斯(NB)、线性SVM和MLP。(需要注意的是,并非所有算法都是基于概率的算法,像是KNN和SVM,它们的预测置信值是用其他参数计算得到的。)
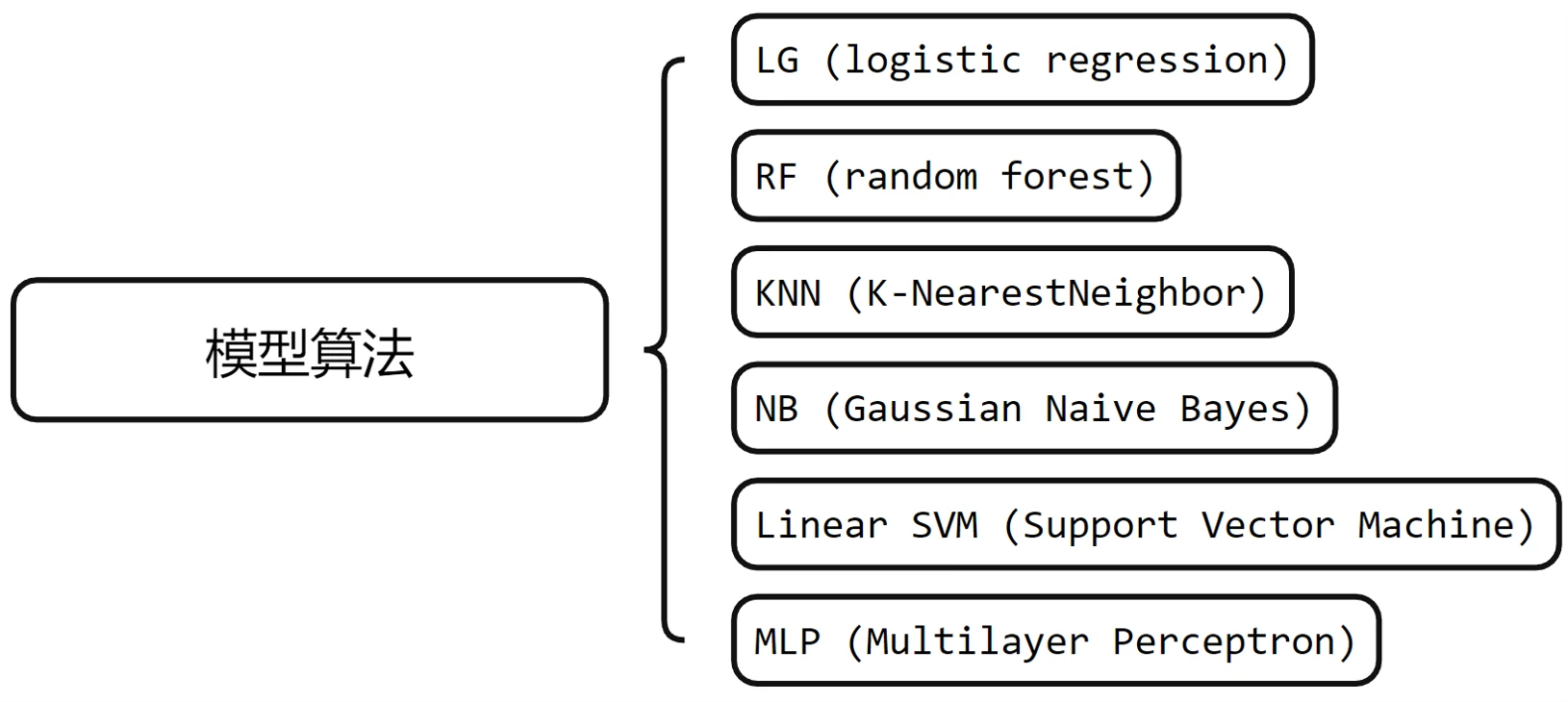
模型算法
之后,论文还规定了实验所用的设备。论文团队评估了四种不同平台的性能,并与笔记本电脑作为参考设备进行了比较。它们在处理器性能、内存等方面具有一定的差异。
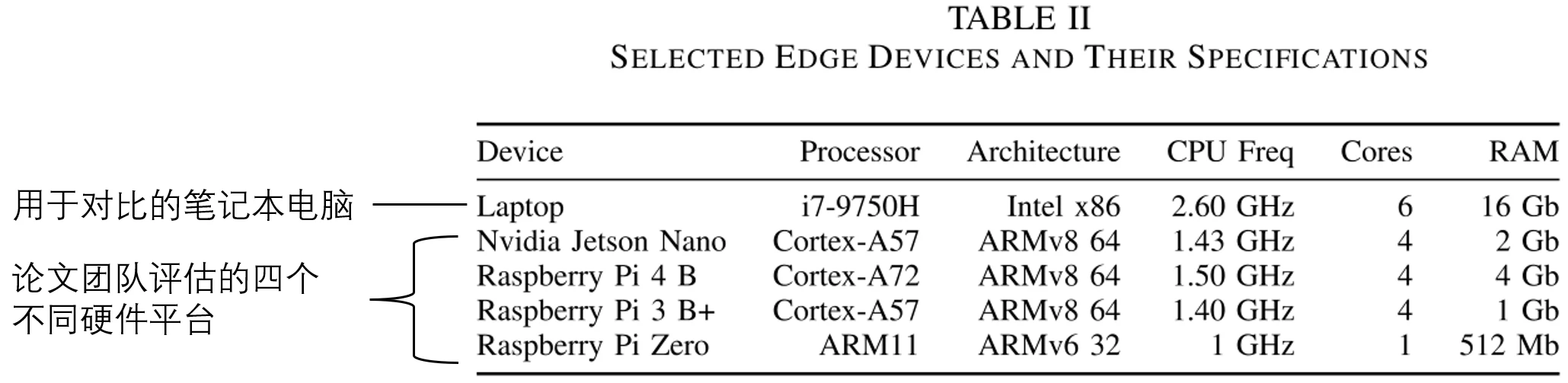
边缘设备选取
图5是论文在模型级联方面做的一些参数设置,实验中,每一台边缘设备都会搭载如图5所示的级联模型。我们从图中主要关注两个要点,第1,整个模型集群一共只有3个模型,而且这三个模型做分类任务所用的特征数量,从上到下是逐渐增加的。第2,给前两个模型设置的置信阈值
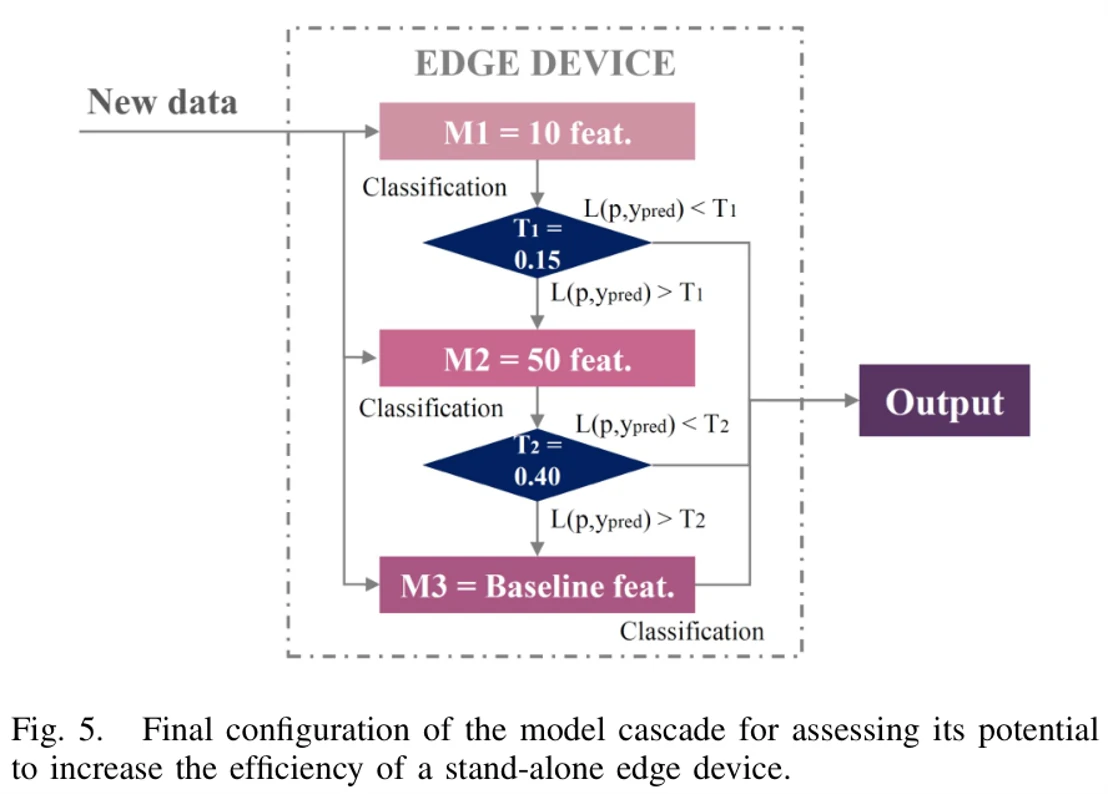
Fig.5-模型级联配置
除了上述实验设计,论文中还规定了实验的其他条件,比如,输入数据预处理方面,有哪些步骤,模型怎么进行特征选择,分类任务用什么框架,运行时间怎么测量,等等:
- 采用了中值数据过滤、数据分割、特征计算、归一化和推理任务等步骤;
- 每个模型采用Chi2过滤法进行特征选择,尽可能让模型做预测用到的特征都是对预测来说最有用的特征;
- 在所有实验均在相同的软件环境和条件下进行;
- 用
Scikit-Learn框架实现分类任务; - 使用Python的库
Timeit来测量运行时间; - 所有实验在CPU下进行。
实验执行与结果分析
论文主要从三个方面分析了实验结果:
- 分类准确性的评估;
- 模型级联三个不同实现方式的对比;
- 不同平台在执行分类任务时的计算成本。
1. 分析不同模型的分类准确性
论文每个实验组10次运行的预测结果取平均,并且用macro F1分数衡量模型预测的准确性。
同时,除了并行、顺序、混合三种不同的模型级联方式之外,论文还加入了一个参考模型和用stacking技术构造的模型,对比了这五种不同模型组合方式的预测准确性。级联模型的每一层还用了分层五重交叉验证程序来确保实验的可靠性。
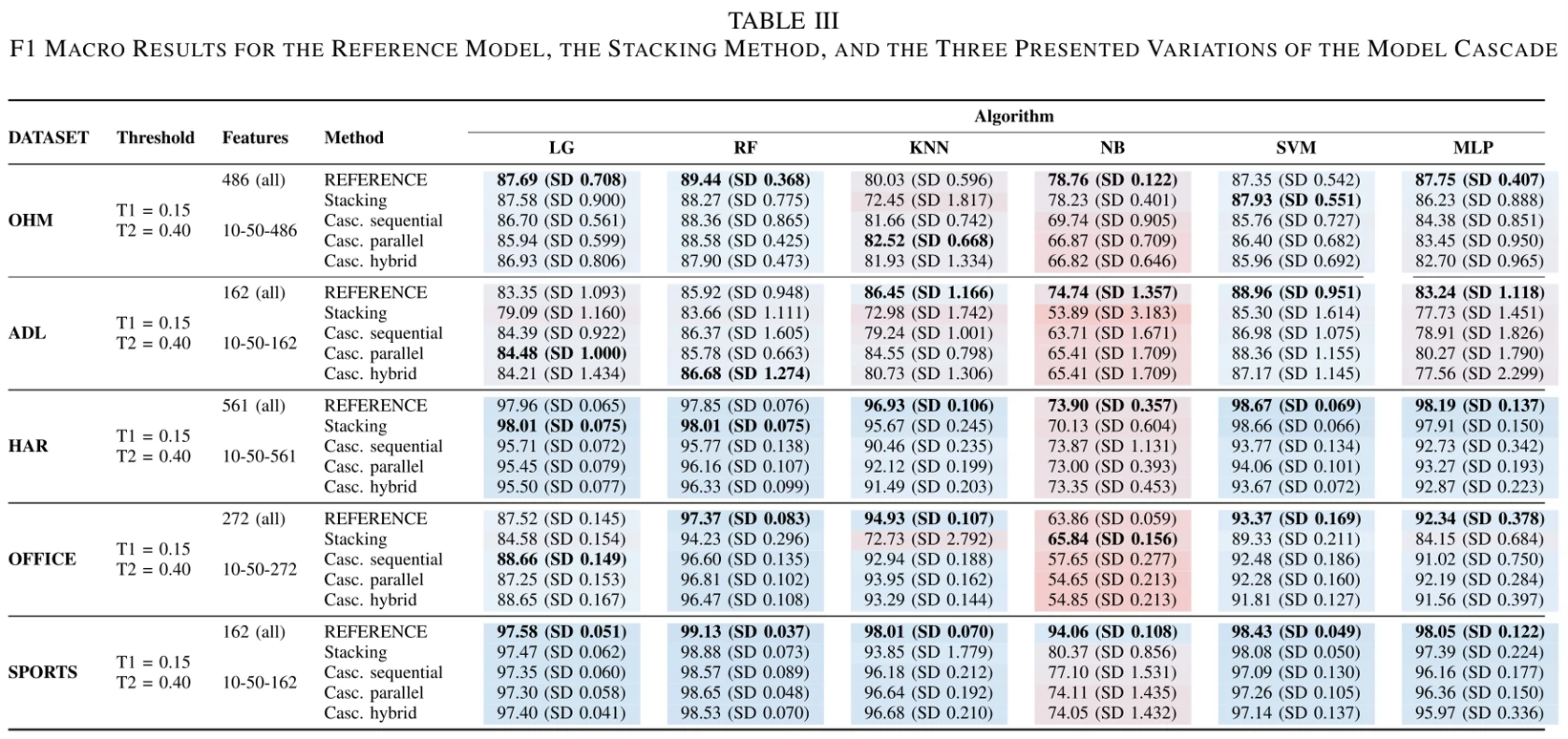
表3展示了六种不同模型、五种不同的模型组合方式在五个不同的数据集上做预测得到的macro F1分数。红色代表这个分数比较低,蓝色代表这个分数比较高。
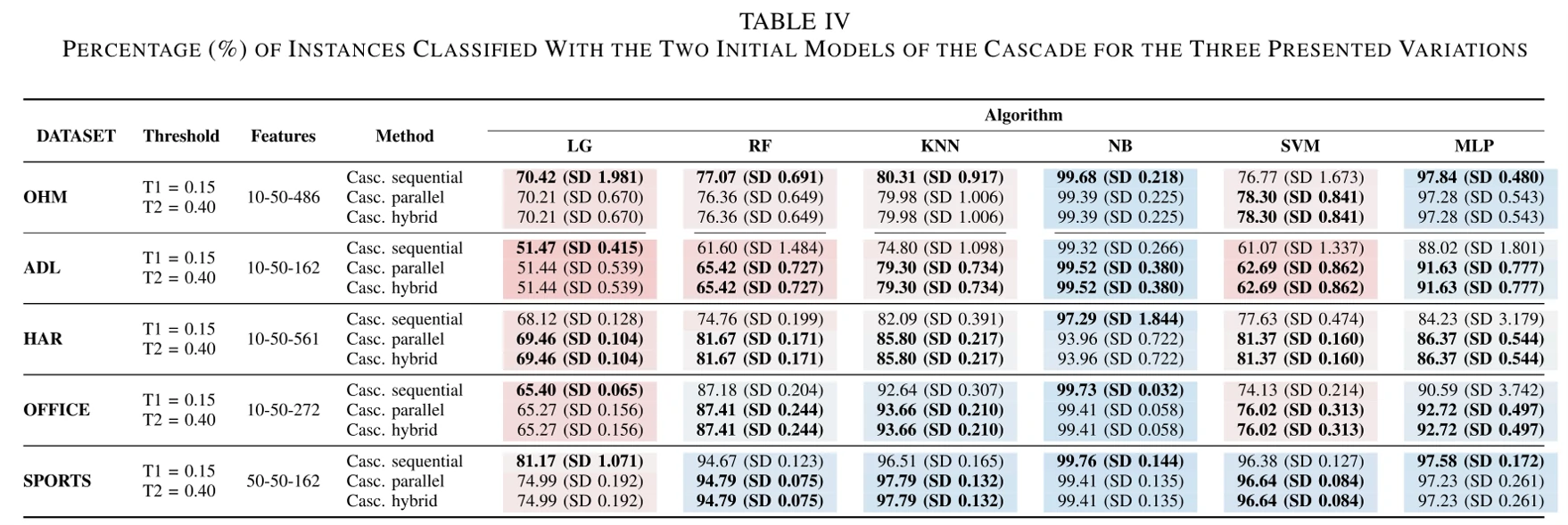
表4展示了六种不同模型、三种模型级联方式在五个不同的数据集上做预测时,只用前两个模型就完成了分类的样本占比。红色代表占比较低,蓝色表示占比较高。
论文通过这两个表得到了如下结论:
- LG、RF和SVM模型在所有数据集的预测中表现最稳定,它们的macro F1分数基本一致。
- 论文提出的模型级联方法,以及Stacking方法,如果用MLP和KNN模型去做分类,那么它们预测的准确性普遍比参考模型要差。
- 采用NB算法的模型预测准确性最差,论文认为这个原因需要结合表4来看。可以看到,如果用NB算法,那么绝大部分的样本都在级联模型的前两个模型被分类完毕了,几乎所有样本都没有经过最后一个能力更强的模型。于是论文觉得置信阈值t在这里调得不好,所以产生了这个结果。
- 论文提出的模型级联方法取得了和Stacking技术相似甚至更好的分类结果。
论文还做了两张表(表5和表7),比较了五种不同模型组合方法的预测准确性。
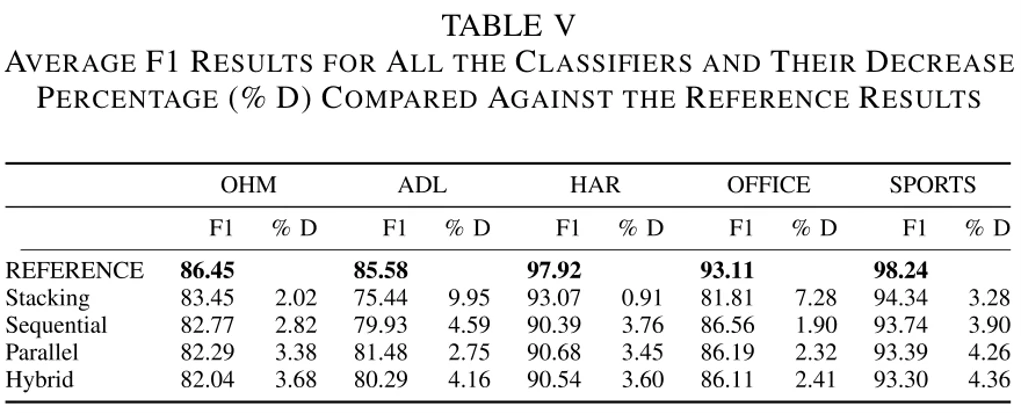 、
、
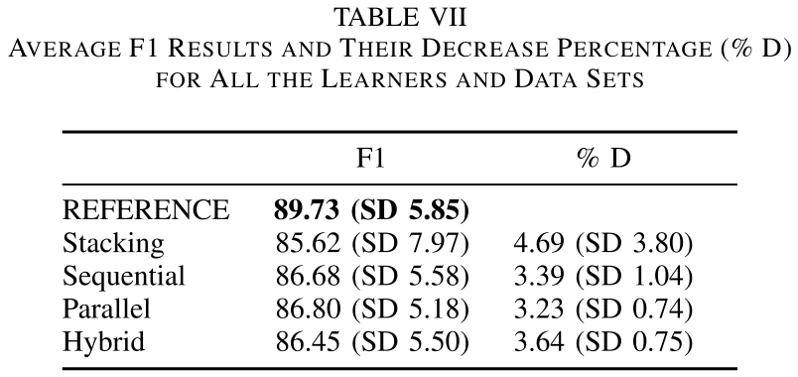
表中
从这两张表我们可以看到,论文提出的模型级联方法,以及Stacking方法预测的准确性平均来说还不如参考模型,模型级联方法的分数比参考模型平均低3.42%,Stacking比参考模型平均低4.69%。
论文说,虽然我们提出的方法在分类准确性上比参考模型低一些,但我们方法的优势不在提高准确率,而是在于样本用更简单的模型就能完成分类。论文中的表6展示了三种模型级联方法下,只用前两个简单模型就完成分类的样本占比。

可以看到,论文提出的这个方法,让80%左右的样本只用比参考模型简单的多的模型就完成了分类,而这个降低模型复杂度的代价仅仅是让预测准确性有一个4%左右的降幅。
2. 模型级联三个不同实现方式的对比
看完了分类结果,接下来论文从第二个方面来分析实验,就是对比模型级联三种不同的实现方式,希望从中找到一个最好的。选择最好的方法主要考虑两个因素:一是分类的结果要好,二是分类的效率要高,在这里认为,级联的模型中最初始的简单模型分类的样本数量越多。分类的效率就越高。
根据刚才我们展示的表5和表6,论文得到了一些初步结论:
- 混合方法相比顺序方法和并行方法来说没有表现出优势。
- 并行方法和顺序方法总体上获得了更好的分类结果。
- 并行方法和混合方法中不同级别的模型分类的样本占比是一样的,毕竟它们在前面两个模型上的结构是一样的。
论文想要在最好的分类结果和最高的分类效率中找一个平衡,于是论文做了一个Pareto多目标分析。
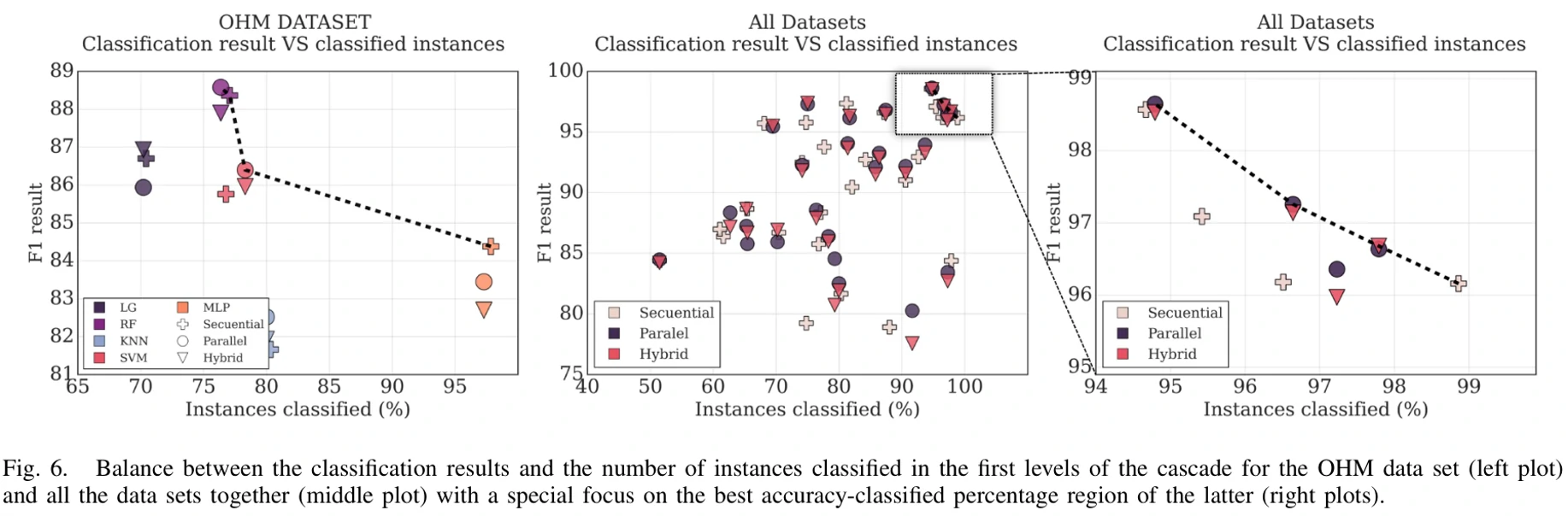
图6展示了论文团队自创的OHM数据集和实验中用到的所有数据集中,分类准确率和被简单模型分类的样本占比的关系。最右边这张图是中间的这张图右上角一部分放大后的图。图里面的虚线就是Pareto frontier,中文翻译叫帕累托前沿,它反映了分类准确率和分类效率最大化之中寻找到的最佳解决方案,每个方案都包含方法名称、对应的F1分数,以及初始模型分类样本的占比。把这些用帕累托分析得到的最优解整理出来就得到下面这张表8。
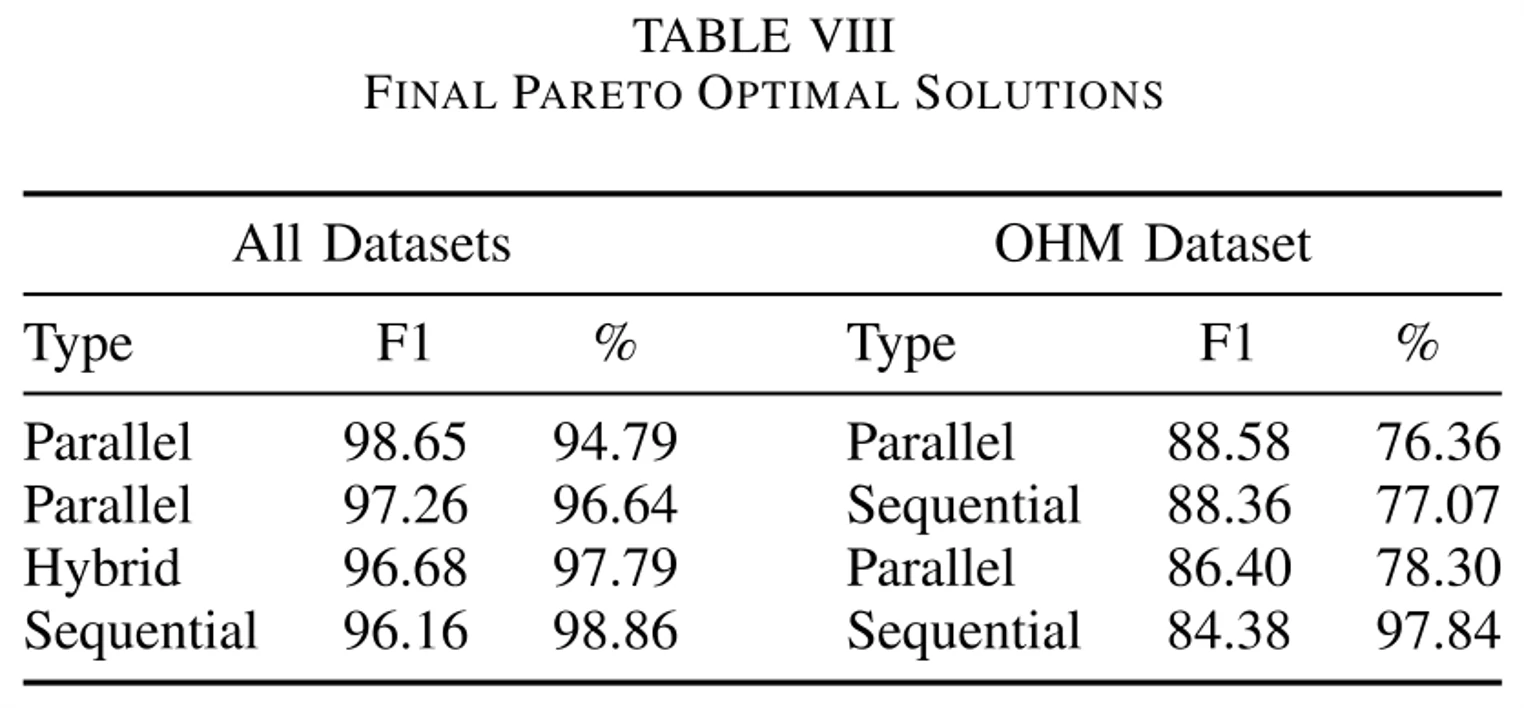
根据表8的数据,论文认为顺序方法和并行方法在这三种模型级联方法中占据主导地位,并且并行方法是最容易成为最优解的方法。
3. 衡量计算成本
论文之后还通过测量边缘设备在分类任务上花费的时间,来阐明论文提出的模型级联方法在分类任务中节省时间和资源的潜力。
刚才我们讲到,论文通过帕累托优化过程,认为并行方法在分类表现和分类效率上权衡得比较好,于是论文团队在这里拿并行实现的模型级联方法和参考模型,在团队自创的OHM数据集上比较计算成本,这个计算成本是用处理和分类新的数据样本需要的实际时间来衡量。
论文在这里把数据集中的1000个样本按照80%-20%的比例分成训练集和测试集,对比二者对测试集里200个样本进行分类所花费的时间。
为了确保实验结果的可靠性,论文让每个实验组总共运行了30次,计算平均消耗时间。
表9列出了两种方法在5个不同的边缘设备在OHM数据集上运行的时间。
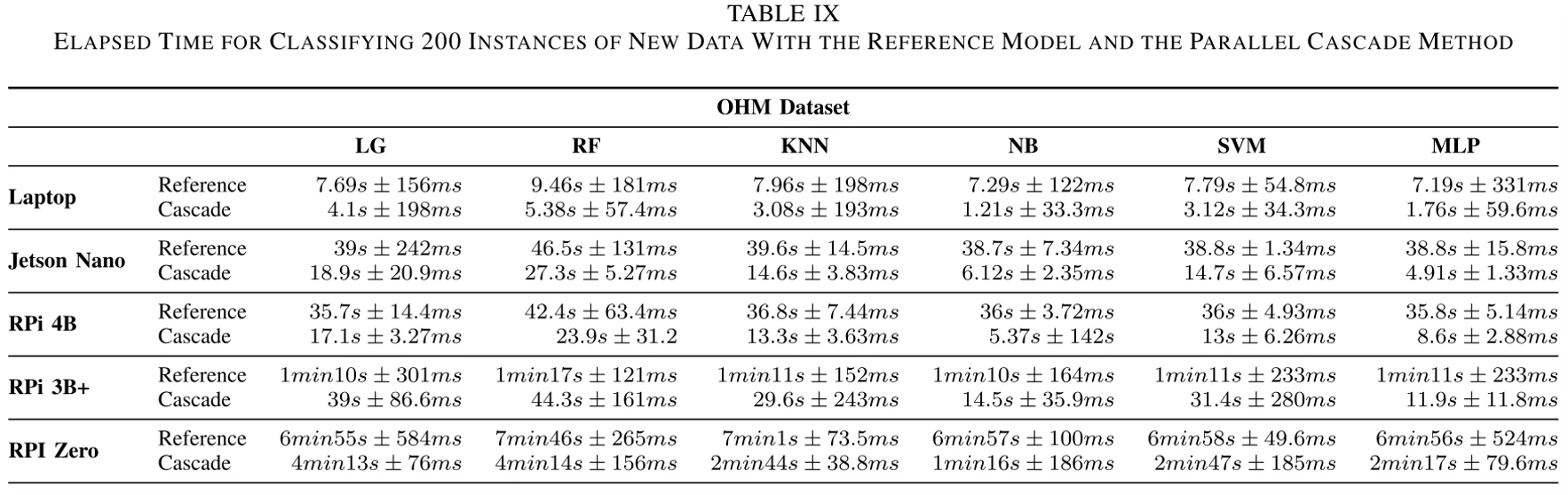
从表中可以看到,相比参考模型,论文提出的模型级联方法在数据集上的运行时间明显更短。
论文还做了一张表10来展示模型级联方法的运行时间相比参考模型,具体节省了百分之多少。运行时间的节省幅度也和之前的表一样用颜色标识,红色代表节省幅度相对较低,蓝色代表节省幅度相对较高。
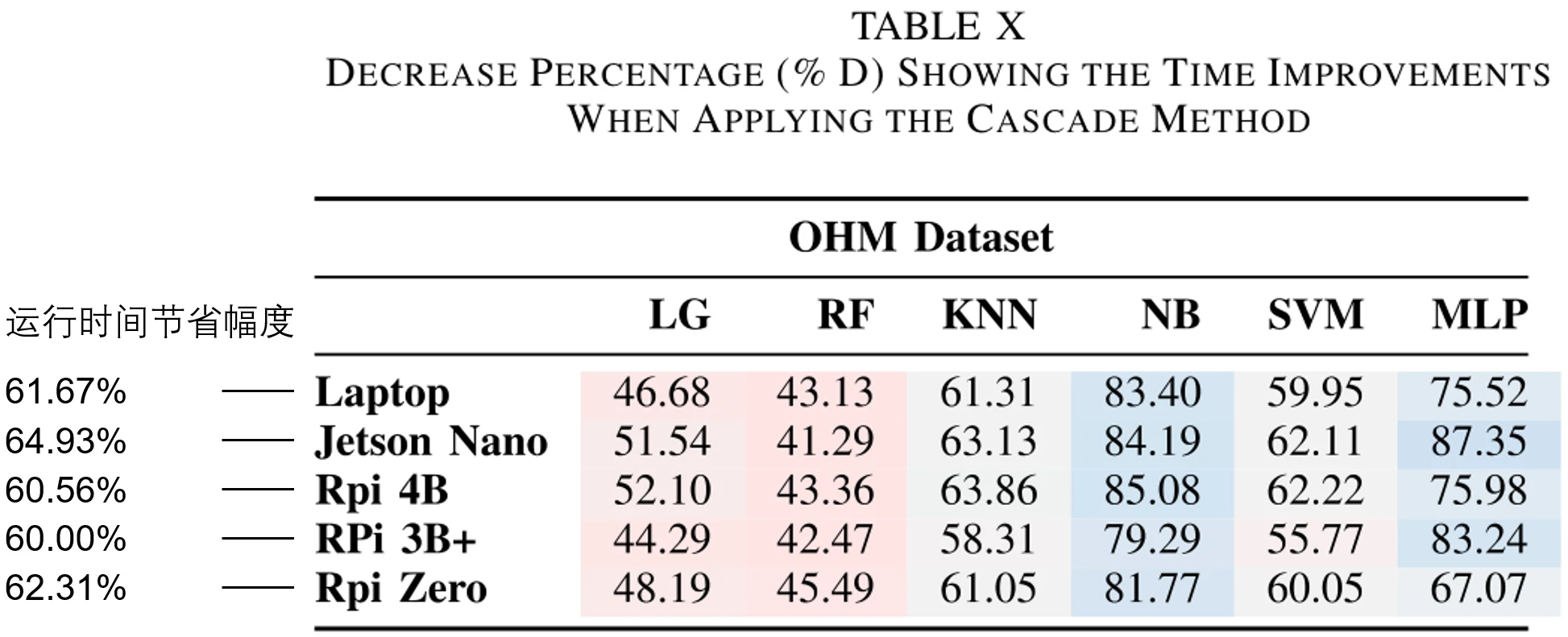
可以看到,模型级联方法在大部分情况下,相比参考模型,能节省超过50%的时间。结合前面展示过的表来看,在级联模型中,被前面简单模型分类的样本占比越高,运行时间节省的就越多。
论文还对所有算法的运行时间做了平均之后,得到了模型级联方法在各个不同边缘设备上相比参考模型节省的运行时间。(论文没有把这部分数据写在表格里)。论文认为,这些结果表明了,使用他们提出的模型级联方法之后,边缘设备处理人类活动识别的分类任务的数据处理速度得到了显著的提升,而且论文方法最大限度地降低了边缘智能系统的复杂性,提高了系统的可扩展性,让我们能在边缘设备上部署一些原本无法高效执行的复杂应用程序。
4. 实验局限性
论文最后阐述了上文实验的局限性:
- 模型级联的层级数量、每个模型的特征数量、每个模型分类结果的置信阈值都会对结果有重要的影响,论文只是把这些因素都固定下来,没有在这些方面选不同的方案做更多实验。
- 因为实验没有涵盖模型级联各个因素的变化,没有充分发挥各种模型在分类任务上的潜力,导致实验结果可能不是最好的。
- 在衡量计算成本时,是用计算时间来衡量的,而这个结果可能受到边缘设备内部的进行等因素影响。
总结与后续展望
论文在最后总结了前文提出的方法与实验。
在论文工作中,论文团队提出了一种在资源受限的边缘设备中,通过模型级联技术,优化和提高分类任务性能的方法。也就是说,论文主要解决的问题是,如何提高边缘智能解决方案在嵌入式人工智能不同应用场景中的可用性和效率。为此,论文分析了判别模型级联方法的三种实现方式的适用性,并通过实验分析,比较了所提出的方法和参考模型、Stacking方法在人类活动识别任务应用中的性能。
实验结果表明,论文提出的模型级联方法的结果优于Stacking方法。与参考模型相比,论文提出的模型级联方法大幅减少了运算时间,同时让检测准确率保持在一个可接受的范围。论文认为团队提出的方法为低延迟、高能效的应用铺平了道路,使边缘技术真正实现了智能化。
在后续工作中,论文团队希望进一步探索异构边缘节点的层次结构是否适合容纳每个级联层次,并确定最理想的通信机制。此外,团队还计划将计算要求较低的模型从边缘节点移植到终端设备,并在那里分配级联系统的一部分。团队希望在真实世界的在线分类场景中研究拟议解决方案的部署情况,以扩展其及时满足边缘要求的潜力。