论文阅读:《Deep Reinforcement Learning-Based Air-to-Air Combat Maneuver Generation in a Realistic Environment》
本文章内容改编自笔者于2024年6月15日的实验室组会中,和其他三位同学做的论文汇报。这好像是我第一次在组会做论文汇报,而且这个“四个人汇报一篇论文”的主意好像是我提出来的,老板竟然还同意了,现在越想越难绷。
论文信息
汇报所述论文是由几位韩国人于2023年发表在IEEE Access上的一篇文章(IEEE Access是个什么水平,大家懂得都懂)(前面这句话是我博士师兄说的,不是我说的)。
DOI:10.1109/ACCESS.2023.3257849
论文主要介绍了一种方法,让智能体操控的飞机在信息不完整的环境中通过机动赢下狗斗。论文主要有如下特点:
- 训练所用的环境不是基于传统的MDP搭建的,而是基于POMDP创造了一个部分可观测的环境;
- 论文采用的强化学习算法是SAC,把长短期记忆网络(LSTM)用在了算法当中;
- 论文将课程学习理论应用到训练过程,提高了智能体的训练效率。
目录
- 训练环境设计
- 网络结构
- 奖励函数与训练
- 实验设计与分析
- 总结
- 扩展阅读
训练环境设计
(本节主编:学生W)
本部分讲述论文是怎么用POMDP(Partially Observable MDP)搭建训练环境的。
论文的训练环境是基于POMDP的,所以我们首先介绍POMDP和传统MDP的区别。在 POMDP 环境中,智能体不能再获取全部状态信息,而是用观测函数,从观测集合
POMDP可以用一个六元组
POMDP具有非定态和次优特性(每次从POMDP中获取的观测值是不确定的,一些统计量会发生变化),智能体在POMDP环境中训练也比较困难。关于如何让智能体在这种环境中高效地训练,论文提出了一种解决办法,就是在训练过程中用上循环神经网络,让智能体除了记录当前时间的信息,还能存储上一个时间节点的信息。在具体实践中,SAC算法加上LSTM是训练效果比较好的方式,其中SAC是一个比较流行的强化学习算法,LSTM是长短期记忆网络,是循环神经网络的一种,我们会在下一个章节展开来讲LSTM的有关内容。
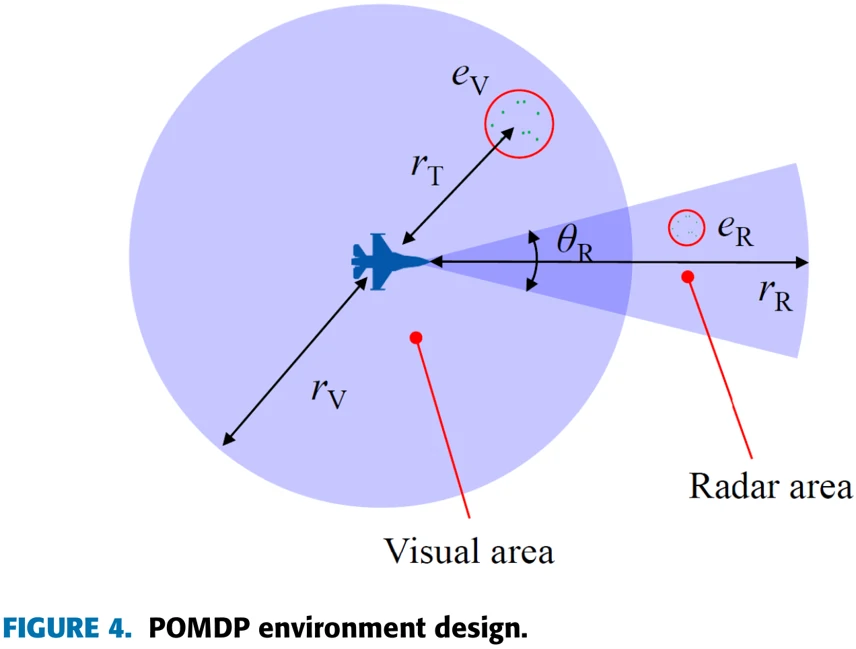
图4描述了论文中训练环境是怎么体现POMDP特性的。对我们的飞机来说,观测环境靠两种传感器,一种是检测短距离的视觉传感器,另一种是能够检测正向相对狭窄但距离较远的信号的雷达传感器。
在论文中,相机的探测范围、误差用
说完POMDP,我们再来看论文中环境具体是怎么设计的。
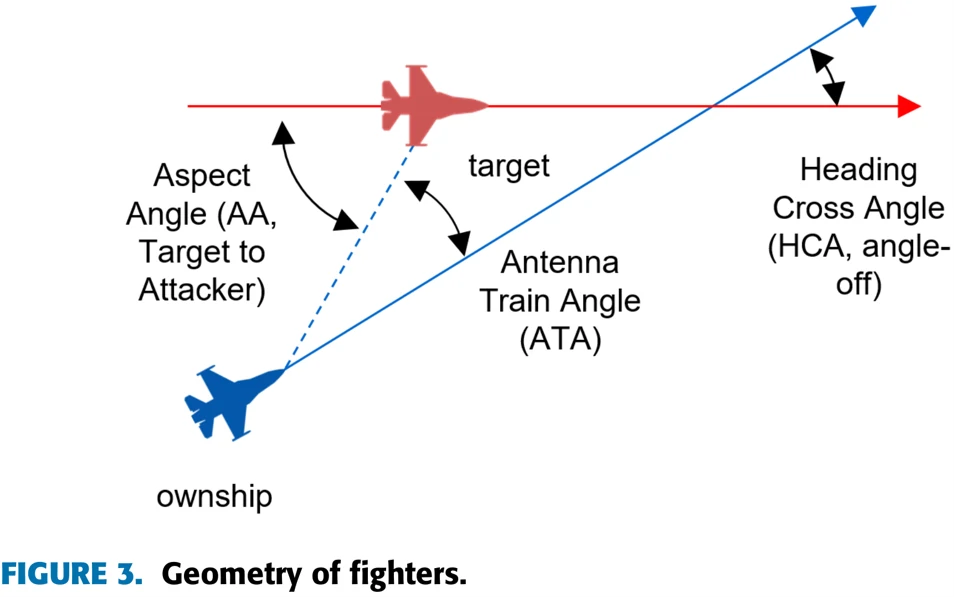
图3展示了作战环境中有关两机相对位置的参数。在这篇论文中,蓝机代表用RL训练的飞机,红机代表采用固定策略的敌机。图中共有三个角,其中AA是敌机机尾和两机连线的夹角,ATA是本机机头朝向与两机连线的夹角,HCA是两机机头朝向的夹角。
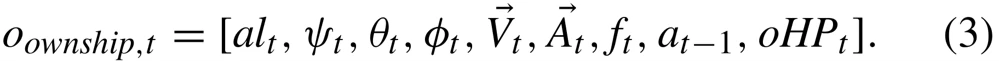
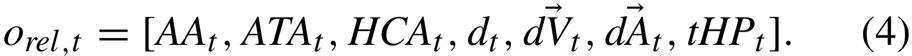
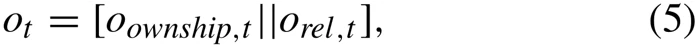
环境状态空间由本机的信息和敌机的信息组成,本机信息包括高度、三个姿态角、速度矢量、加速度矢量、剩余燃料、上一次采取的动作、本机血量。敌机有关信息包括AA、ATA、HCA三个角、两机相对距离、相对速度矢量、相对加速度矢量、敌机血量。因为整个环境是一个POMDP环境,所以敌机的有关信息有时会拿不到。当敌机远离本机探测范围时,敌机有关的信息就不会提供给智能体。
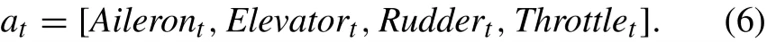
动作空间包括副翼(Aileron)、升降舵(Elevator)、方向舵(Rudder)、油门(Throttle)四个信息。
整个仿真环境更新信息的频率是60Hz,飞机采取动作的频率是10Hz。
本篇论文描述的环境中,两架飞机都有机枪作为武器,并且对武器的攻击效果进行了量化。
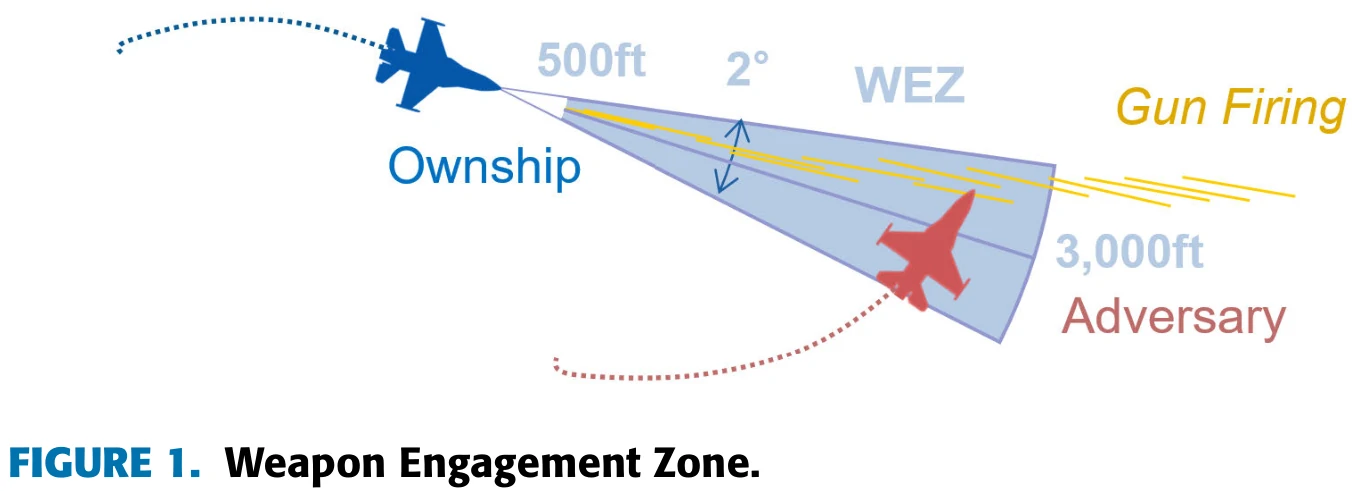
图1展示了武器交战区域。当一架飞机进入另一架飞机500到3000英尺的距离范围,且另一架飞机ATA角小于等于1度时,就会受到来自敌方武器的伤害,公式2展示了飞机在进入WEZ后血量的衰减公式,描述在不同位置下每秒钟会扣除多少血量。不过两机的初始血量是多少,论文没有明确说明。
只要满足以下三个条件之一,对局就会结束:
- 任意一方血量降至0;
- 任意一方的高度低于1000英尺;
- 对局时间到达300秒。
智能体操控的飞机会和基于固定策略的敌机对抗,如果本机在300秒内击落敌机,或者敌机高度过低,或者300秒后本机血量高于敌机,就算智能体一方胜出。反之,则智能体输掉对局。如果300秒后两机都没有坠毁,而且血量相同,则判定为平局。
网络结构
(本节主编:学生B)
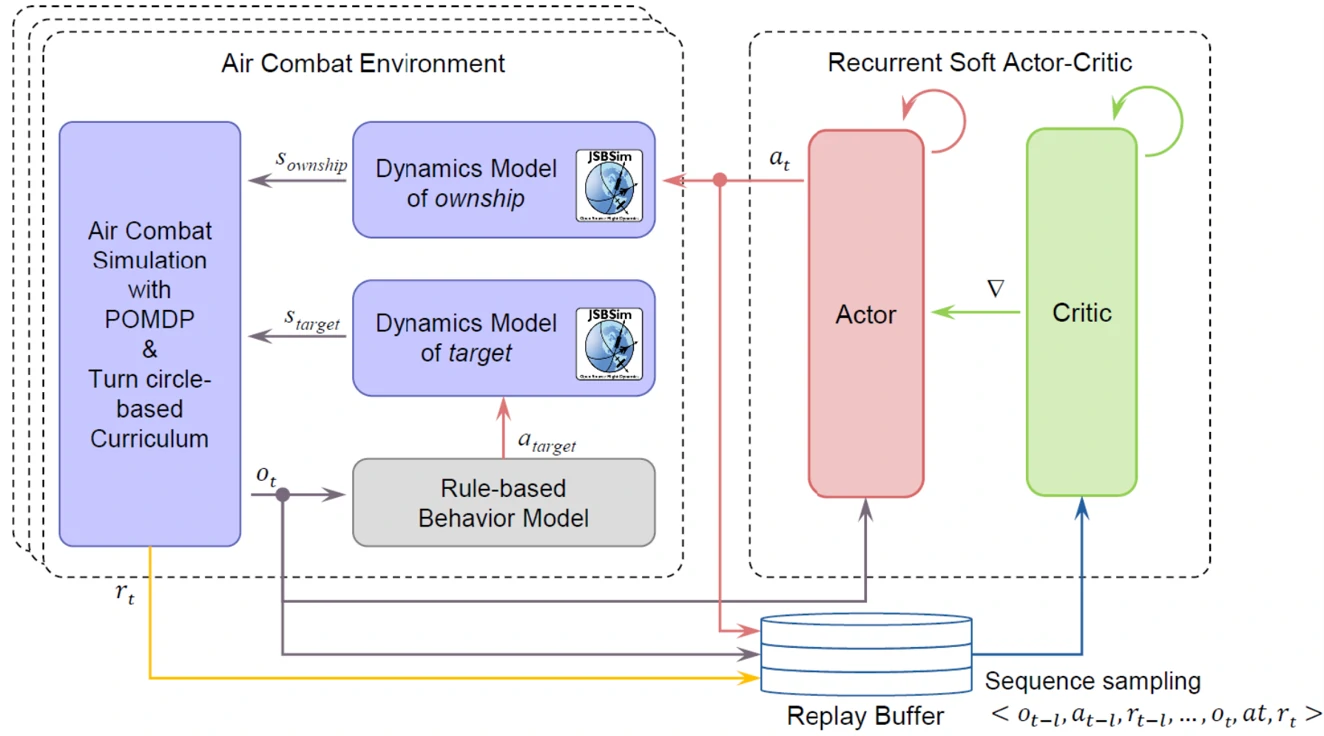
在介绍论文所用的网络结构之前,先给大家展示一下论文训练的整体框架。
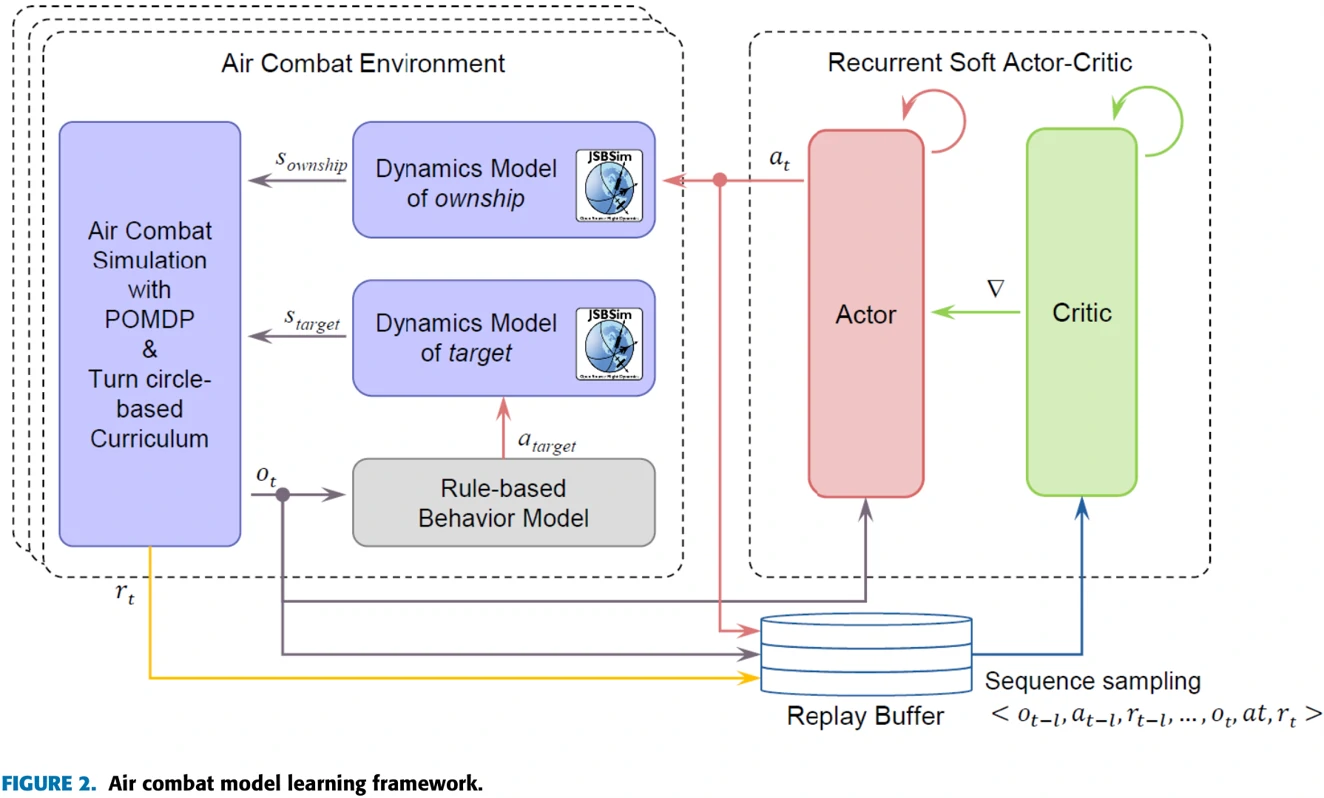
可以从图2右侧看到,论文用的训练算法在SAC算法的基础上加入了循环神经网络的概念,而且经验回放池采样的方式也有变化,每批数据不是随机从回放池中采样,而是按照时间顺序选取一批交互数据。
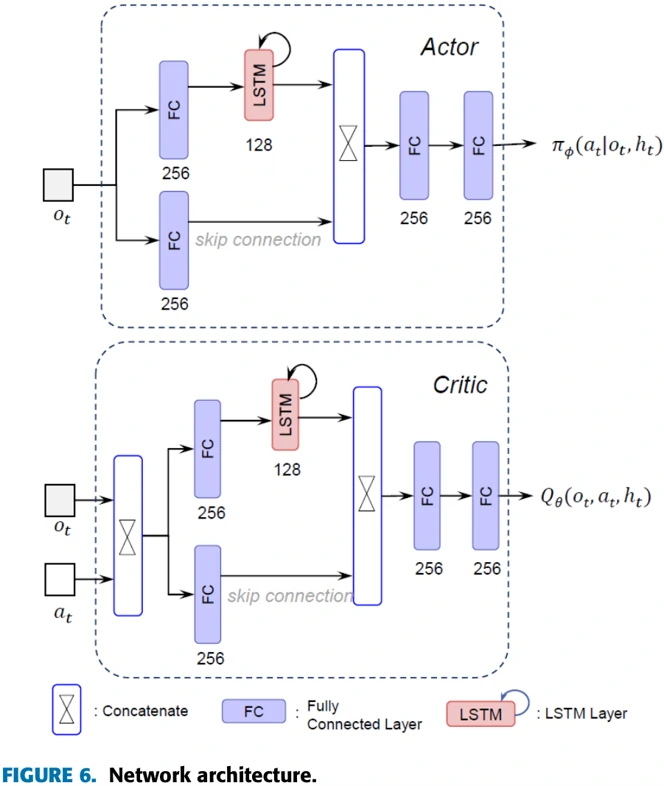
图6展示了论文所用的神经网络结构。Actor的作用是依据观测数据选择动作,Critic的作用是衡量Actor选择动作的好坏。可以看到二者网络结构相似,特点是都有长短期记忆网络(LSTM)作为网络的一部分。每个网络由一个负责内部记忆的循环分支(recurrent branch)和一个前馈分支(feedforward branch)组成,循环分支(recurrent branch)中包含LSTM单元,用以分析飞机该采取什么样的机动方式,以及丢失敌机信息时应该怎么办。
LSTM网络
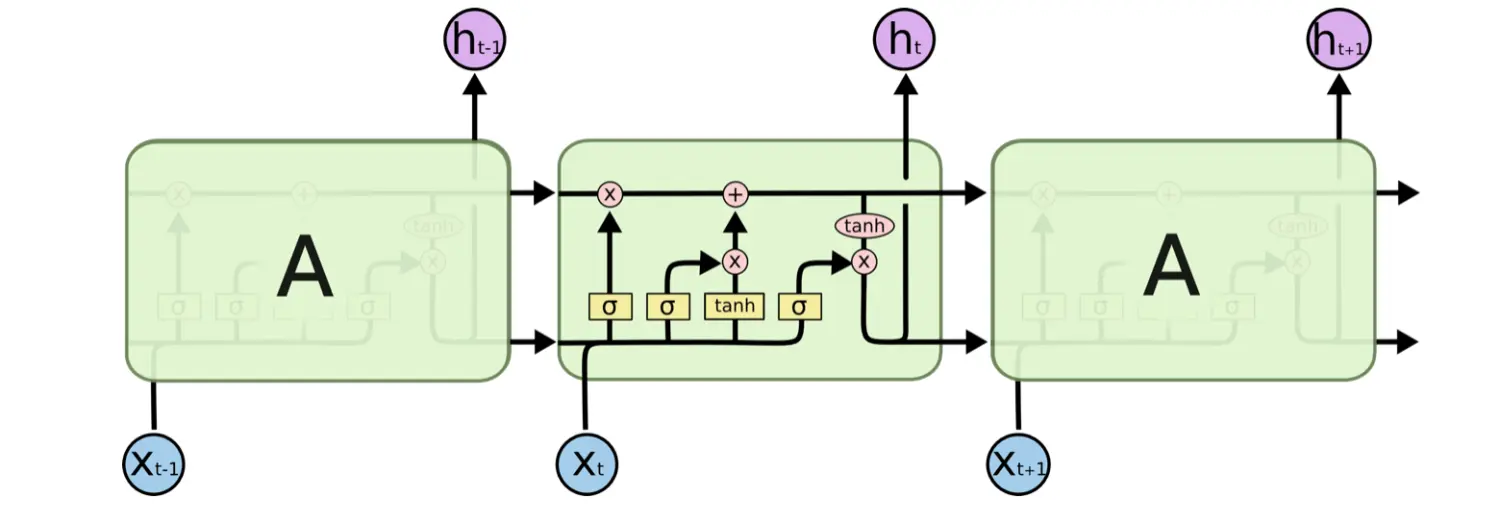
长短期记忆网络是一种特殊的循环神经网络(RNN), 每当读取一个新的输入
传输带(Conveyor Belt)
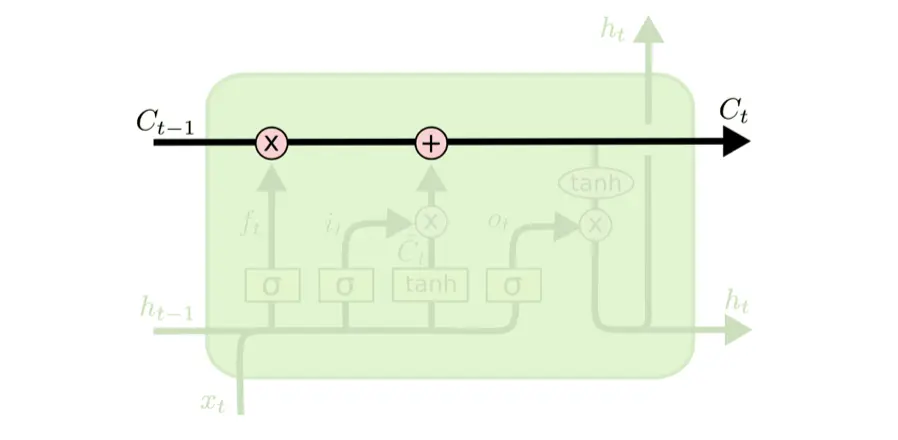
LSTM网络结构比RNN复杂,它使用传输带(Conveyor Belt)将过去的信息送到下一个时刻,并使用“门(Gate)”结构遗忘传输带上的信息或向传输带上添加新的信息。这种结构设计,缓解了梯度消失问题,从而获得比Simple RNN更长的记忆能力。
LSTM网络通过三个门控机制:遗忘门、输入门和输出门,它们控制信息在LSTM中的流动,从而有效地处理长期依赖问题。
遗忘门(Forget Gate)
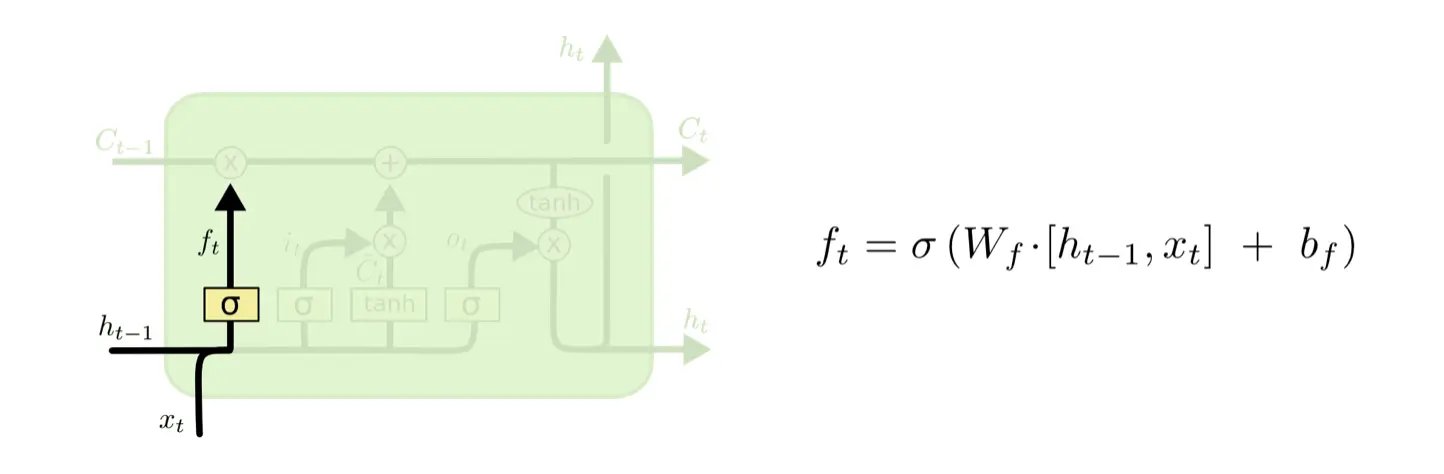
决定过去哪些信息被遗忘。
读取上一时刻状态向量
输入门(Input Gate)
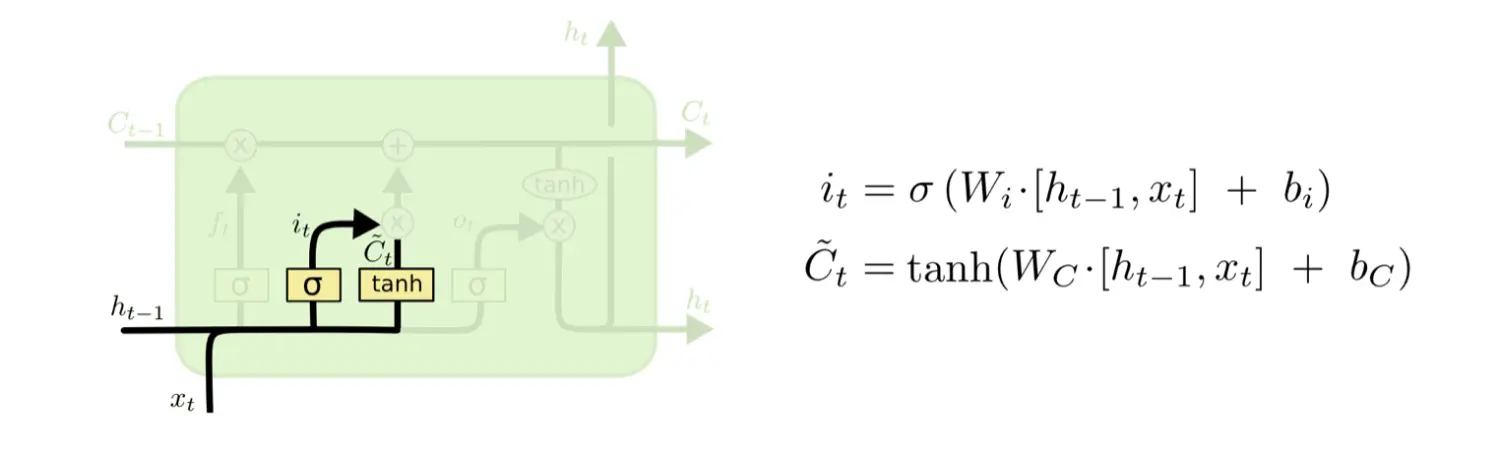
向量
传输带状态向量更新
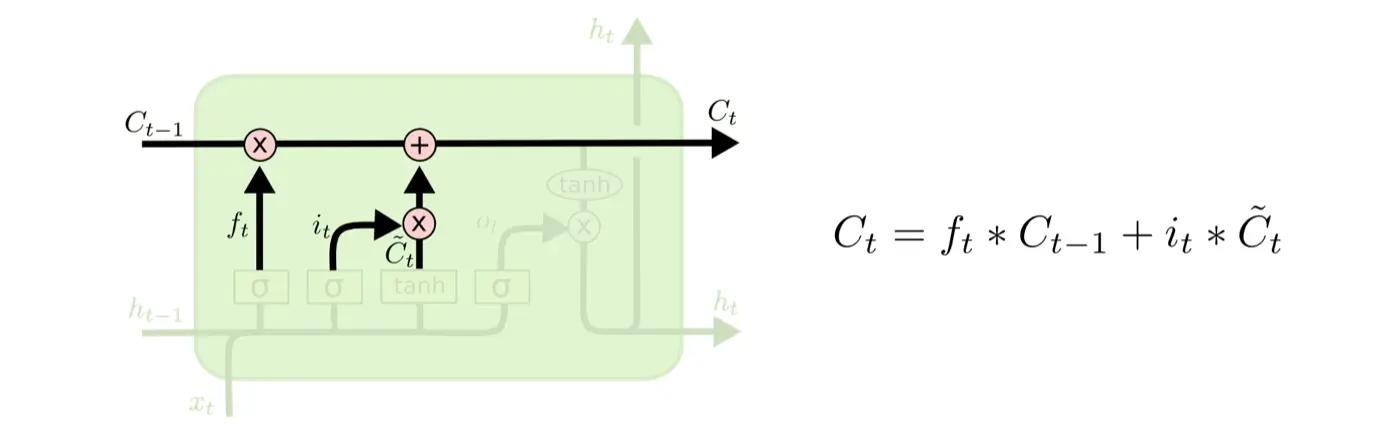
计算得到遗忘门
- 将传输带旧值
与 做逐项相乘,遗忘部分信息; - 将生成的输入值向量
与 做逐项相乘,得到输入信息; - 令
,得到新传输带状态向量。
输出门(Output Gate)
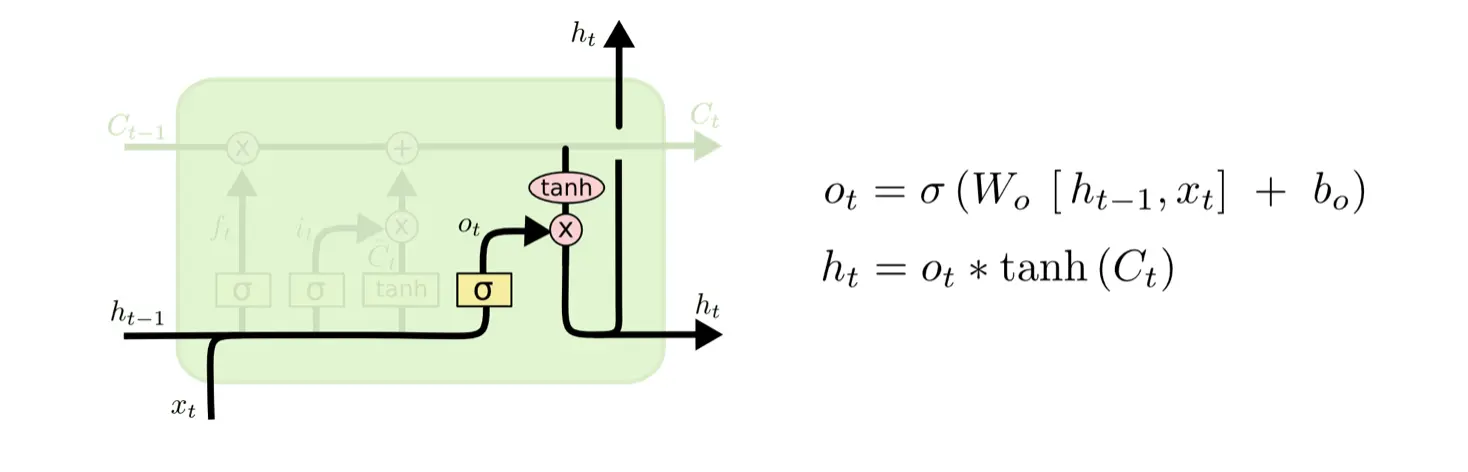
输出门控制决定传输带上哪些信息需要从记忆单元中被输出。将
奖励函数与训练过程
(本节主编:学生L)
奖励函数
首先介绍奖励函数。在论文中,奖励函数由击落奖励、交战区奖励、控制区奖励、高度控制奖励(坠毁惩罚)、稳定性奖励五部分组成。
1)击落奖励
击落奖励顾名思义,当本机使用武器将敌机的血量降至0(也就是击落时),会获得500的奖励,如果被敌机击落,奖励值为-500。
2)交战区奖励

交战区奖励的设置目的是引导本机远离敌机的交战区,让敌机进入本机的交战区。主要的单步奖励如公式7和公式8所示。从限制条件可以看出,这部分奖励在训练前期是难以获得的。
为了让智能体更容易获取这部分奖励,论文额外添加了一个连续的、衡量敌机与本机交战区距离的奖励值。这个密集奖励的思路就是不断缩小攻击区到目标敌机之间的距离,没有直接缩小两机机体之间的距离,这样有利于处理“过冲”问题,也就是本机追赶敌机时有可能冲到敌机前面的问题。
论文里的公式表示的是攻击区到敌机的距离变化与两机之间的距离之比,但是他没有给出明确的计算方法,我们考虑了一些计算方法用于参考,比如利用WEZ扇形的几何中心到飞机的距离表示WEZ到目标的距离,让其不断减小获得奖励。
3)控制区奖励
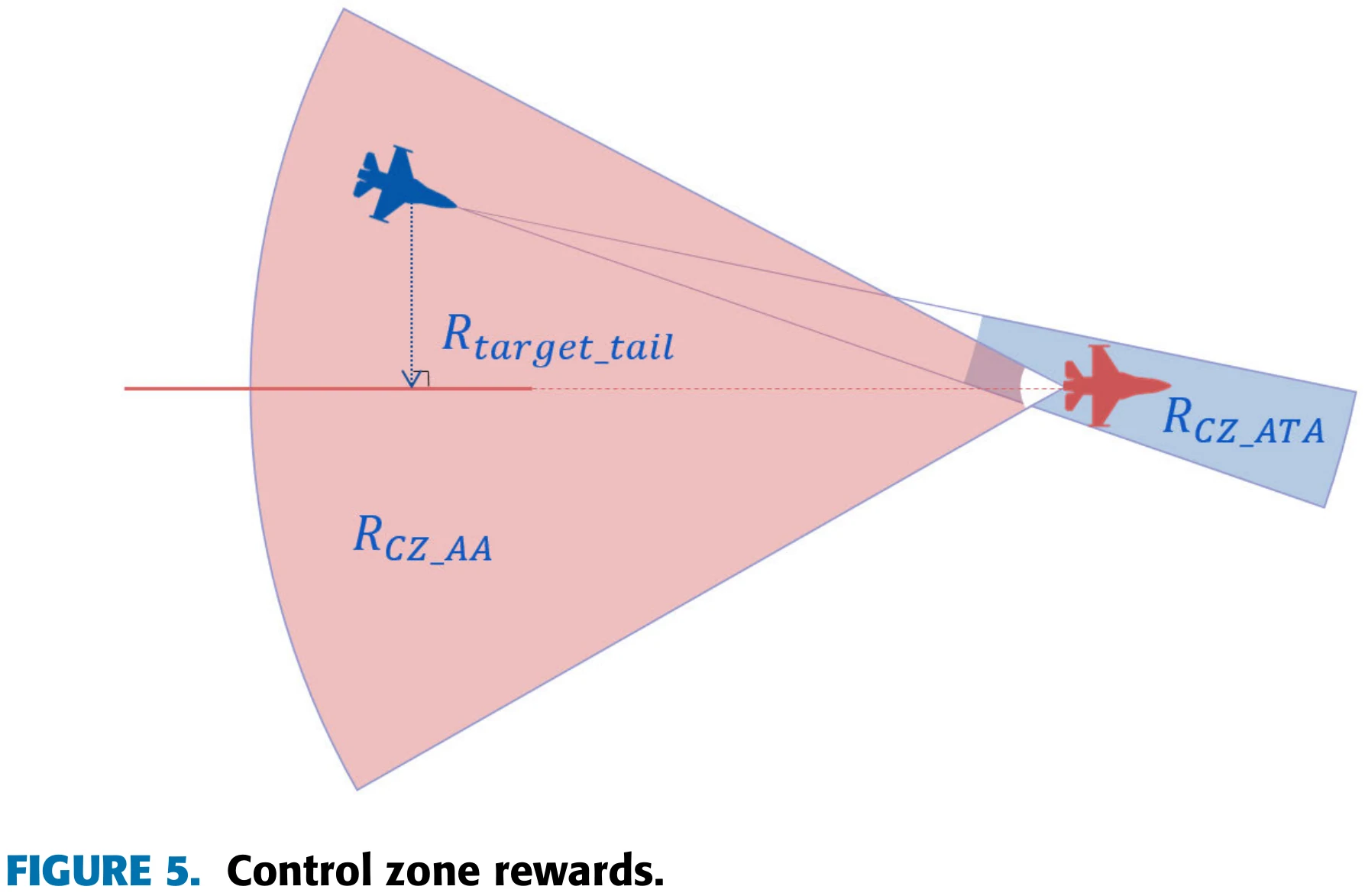

第三个是控制区奖励。论文设置了两个稀疏奖励和两个密集奖励。稀疏奖励使用的ATA和AA,ATA奖励条件使我方飞机观察目标机,AA奖励使我方飞机占领敌机的尾部,如左图所示;这两个奖励也比较稀疏,论文提出的两个密集奖励没有给出明确计算方法,只给了计算思路。密集奖励的第一部分会比较每一时间步ATA减少量和AA减少量,如果ATA减少量更大,则给予奖励,反之则给予惩罚。这是希望本机抢占比敌机更有利的位置。第二部分在敌机后方3,000至5,000英尺的位置创建了一个虚拟的点,在每个时间步计算本机距离这个点是更近还是更远。
PPT中密集奖励的数值是我们举的例子,供大家参考,比如第一部分,如果ATA比AA减小率大,每步就给0.01的正奖励,反之给-0.01。第二部分可以让虚拟的点设置在敌机正后方3000英尺的距离,引导本机飞到这个位置。
4)高度控制奖励
第四个是高度控制奖励,用于防止飞机因高度过低而坠毁,如果本机高度低于1000英尺,对局会结束,并给予智能体-1000的高度控制奖励。在飞机低于2000英尺时,飞机高度越低,惩罚会越大,直到飞机高度低于1000英尺。具体的奖励数值在论文中没有给出,这里的公式是我们给出的一个例子,用于参考。
5)稳定性奖励
第五个是稳定性奖励,用于控制飞机姿态,防止飞机高频率抖动。论文中这个奖励和滚转角有关,滚转角变化越大,给予智能体的惩罚越大。
训练方法
接下来我们讲述论文使用的训练方法。论文采用了课程学习的思路,在训练前期只让智能体面对简单的观测空间,在训练的过程中不断提高难度。论文中的课程学习主要包括了两个要点,第一个要点是确定我方飞机的交战难度,第二个要点是选择两机的位置。
1)确认交战难度(difficulty level determination)
交战难度可以由ATA和AA角度的大小确定,这两个角都是0度的时候也就是正好在敌机尾部,最容易获胜,当两个角都是180度,我方飞机正好在敌机正前面,最难获胜。
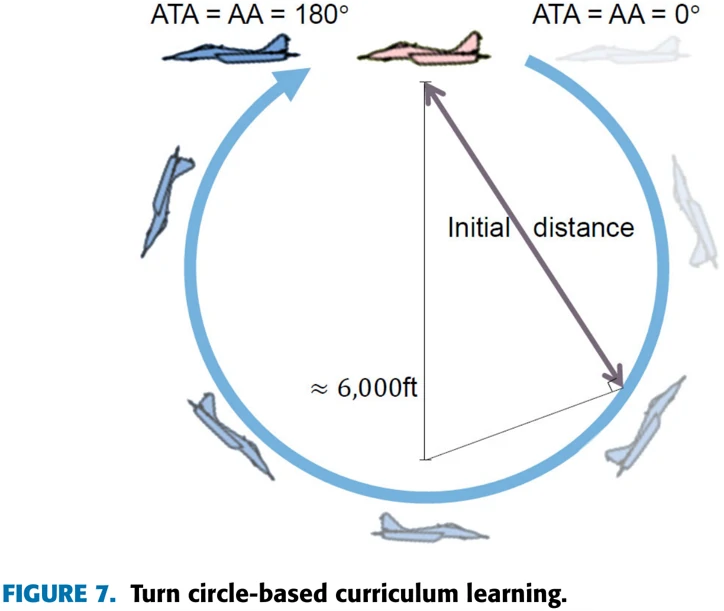

论文算法步骤如图所示,依次将攻击角和逃逸角从0逐渐增加到180,关于距离设置,当角度在15-165度之间时,两机之间的初始距离在以6000英尺为直径的圆上加上一个随机距离。之所以这个圆的直径是6000英尺,是因为第四代战斗机发挥最大机动能力时,转圈的直径就是6000英尺。在15度之内的时候就是在500-1000英尺随机生成一个距离,在学习开始时,如果初始角度小于或等于30度,但训练过程中AA角大于90度,那么这局对战就会结束。这里论文里解释的是“The observation space is limited to improve learning performance”,如果初始优势的飞机在训练过程中陷入劣势,就停止当前对局。
距离和角度设置之后,训练就开始,每进行30轮对局,就统计一次胜率,胜率大于等于70%时,就增大飞机的两个初始角度,继续上述过程,直到飞机在初始角度为180度时也能达到70%的胜率,整个训练就结束。
2)两机位置确定(formation determination)
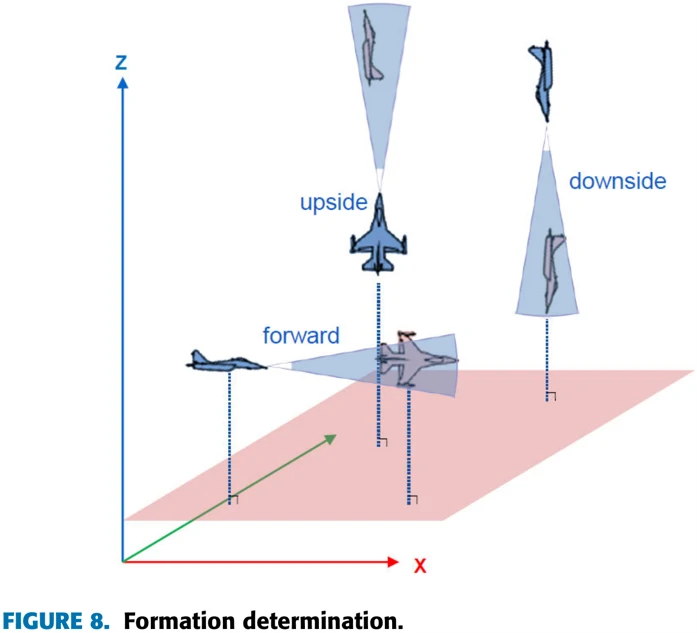
如图8所示,即使确认了距离和角度,飞机的作战难度和操纵性能也会因它们是平飞、上升还是下降而不同。另外,ATA和AA相同时,飞机滚转角也可以设置不同。
考虑到这一点,论文在根据ATA和AA角设置初始姿态时,会从图8所示的前进、上升和下降三种情况中随机选择一种作为初始队形。同时两机的滚转角也是随机确定,让两机以所有可能的姿态开始,每种姿态都对应特定的ATA和AA。
3)敌机机动策略(target maneuvering)
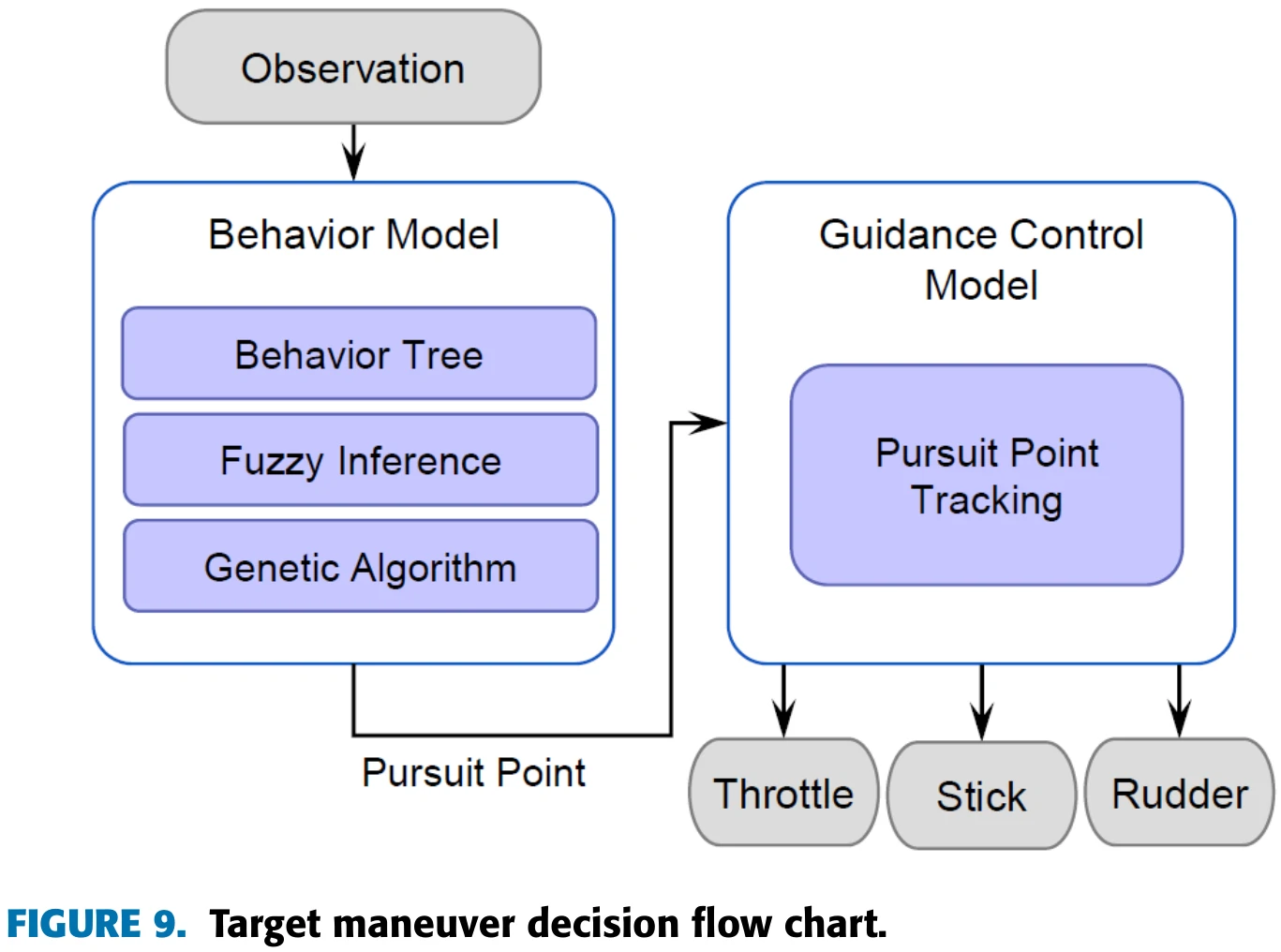
论文里敌机的机动策略采用基于规则的空战模型,分析战场状态,分析行为经验树生成最佳机动方案,生成追击点。利用决策模块输出的四个变量值输入到制导模块控制飞机移动到追击点。
实验设计与分析
(本节主编:笔者)
论文总共介绍了三个实验,对比了三种智能体的训练效果与作战能力:SAC-FC(用SAC算法,网络结构里没有LSTM,只有两层全连接层)、SAC-LSTM(用SAC,网络结构里有LSTM)、SAC-LSTM-no-curriculum(用SAC,网络结构里有LSTM,训练过程不用课程学习)。
除去三个实验,论文也从对局回放里找了一些智能体采取的一些比较典型的机动动作,可以用在实战里面。
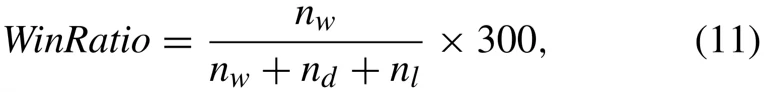
智能体的胜率计算公式如公式11所示,总共统计300局对战,用胜利局数除以总局数得到胜率。飞机在三种不同的态势下作战,优势100局、劣势100局、中立100局。
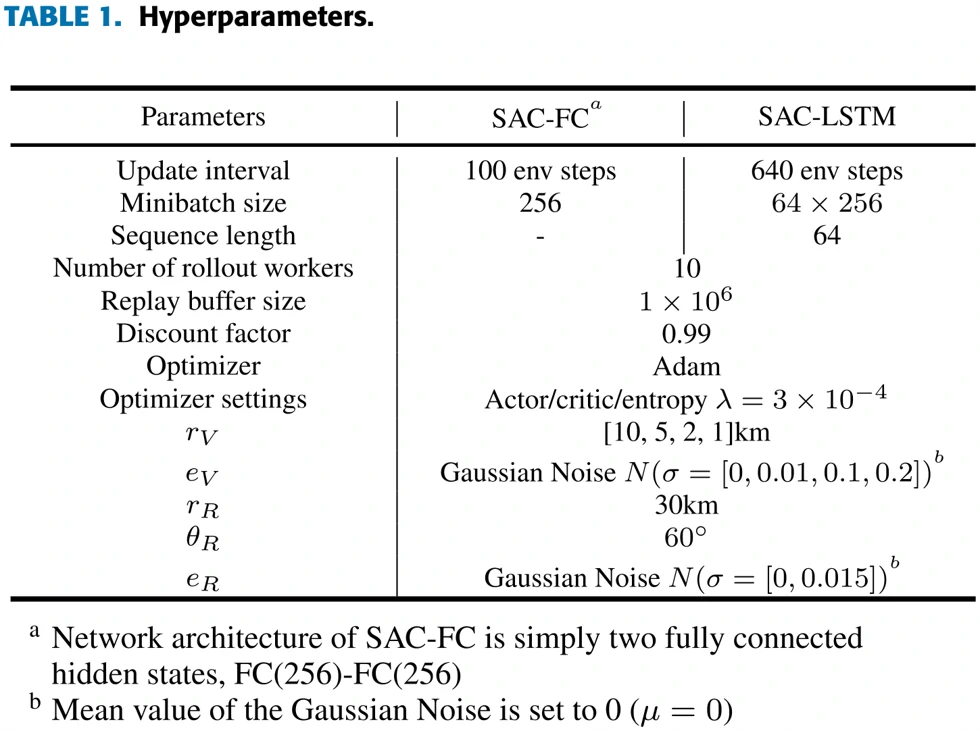
实验超参数如右面表1所示。值的一提的是,陪练用的敌机,采用固定规则,而且即使在POMDP环境下也能获取完整准确的作战信息,而智能体只能观测有限的信息。这样设置的目的是让智能体学会在更加严峻的形势下作战。
1)Range Limitation
飞机探测范围10km、5km、2km、1km,对比SAC-FC与SAC-LSTM训练效果。
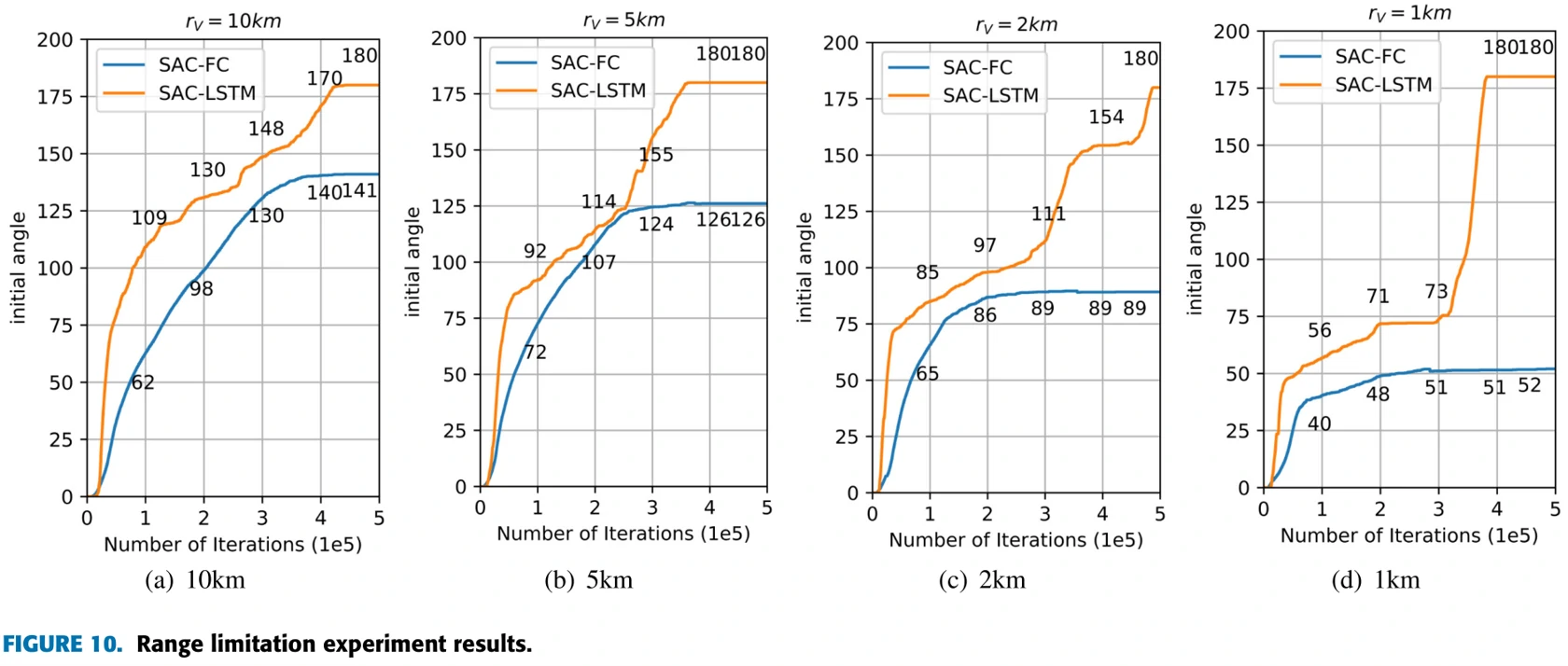
结果:SAC-LSTM都能在规定的有限时间内完成训练目标。探测范围10km与5km时,飞机训练过程顺利(分析:两机距离一般不超过10km,10km时环境近似于MDP;F-16转弯直径约6km,5km时也不太会丢失目标);2km与1km时,飞机有时会不可避免地丢失目标,但依旧完成了训练。1km时训练的受阻情况比较明显,突破瓶颈后训练速度又快了起来。
对于SAC-FC模型,10km与5km时在OBFM与中立态势下能做到70%以上的胜率,但是没有在指定时间内完成训练任务。
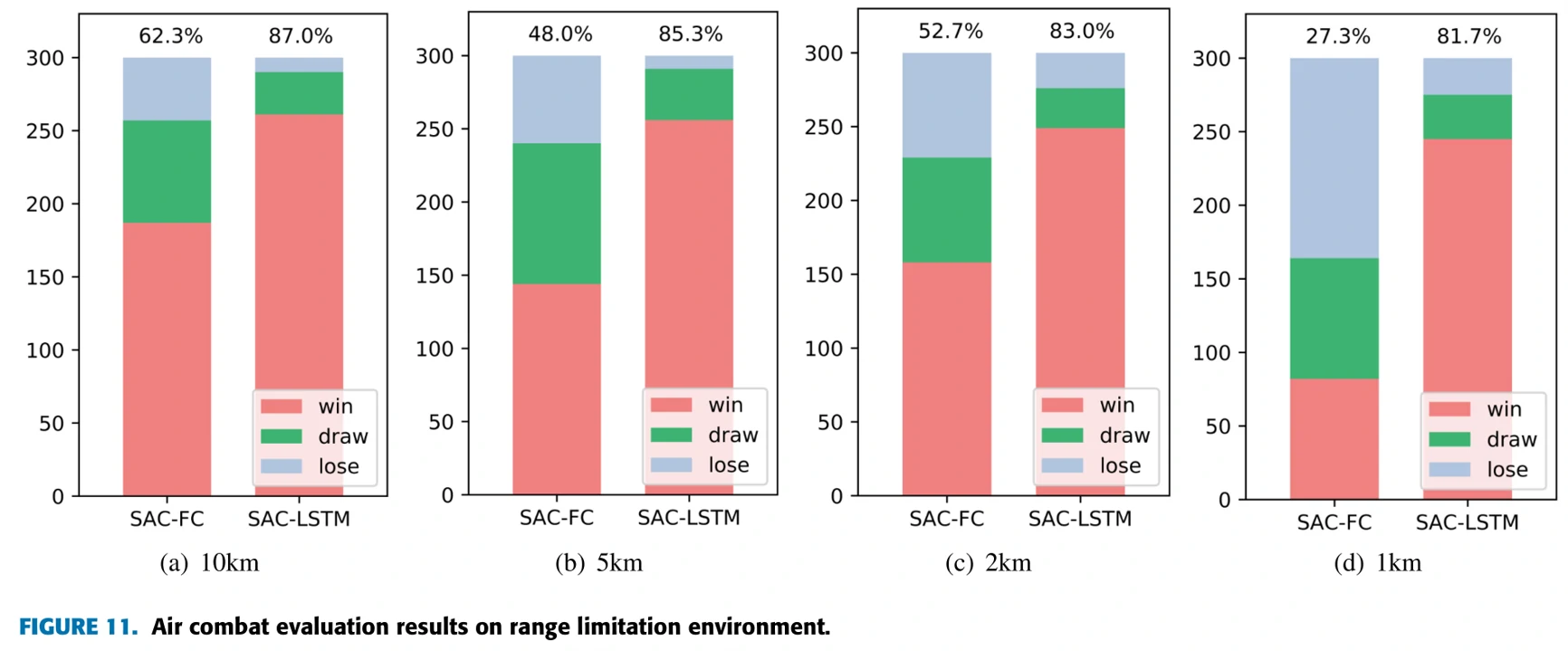
图11展示了中立态势、POMDP环境条件下与基于固定规则的模型的作战胜率对比。SAC-LSTM在所有环境下均能达到80%以上的胜率。SAC-FC胜率比较低,1km时胜率不足50%。
2)Error Injection
测试智能体用给定的方法,能否在探测信息不准确的情况下完成训练目标。探测范围固定到5km,在探测信息中加入标准差为0.01、0.1、0.2的正态分布的噪声。
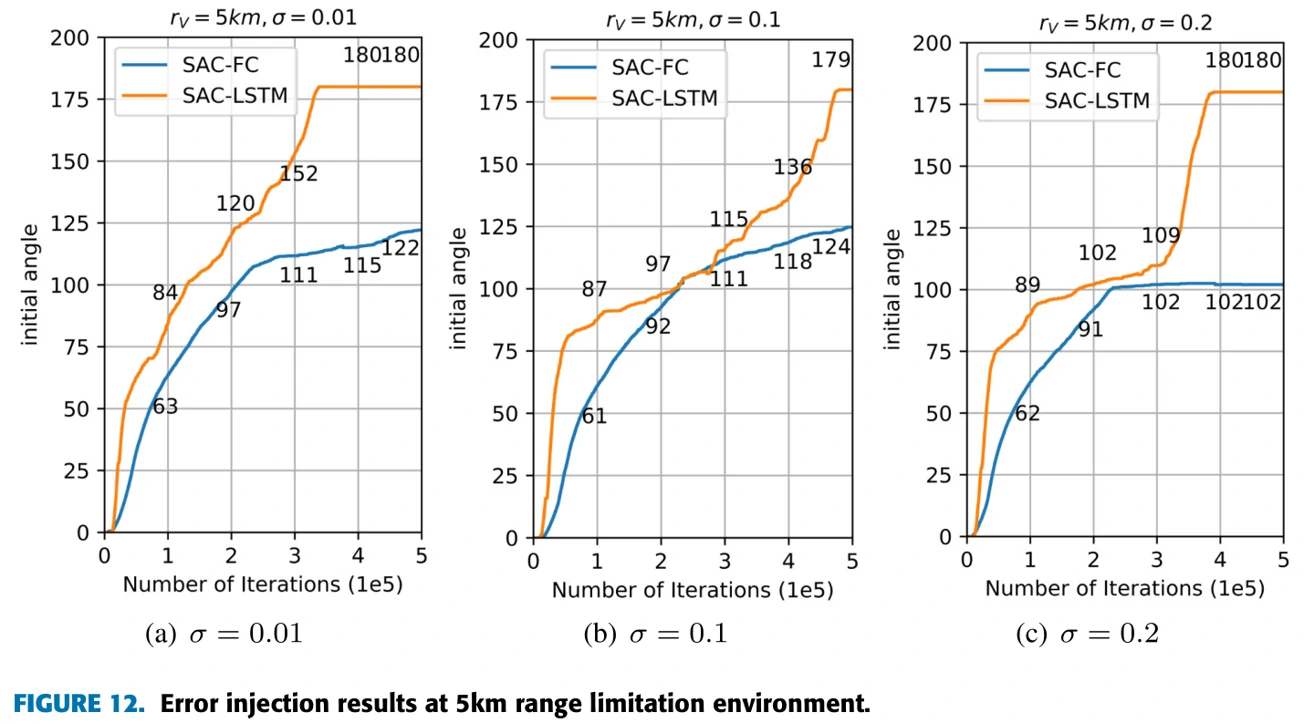
结果:SAC-LSTM在不同噪声条件下均能完成训练任务。噪声0.01和0.1时,训练基本没有阻碍,0.2时在前中期受阻,但后续训练较快,情况比较像实验1)探测范围2km和1km的情形。
SAC-FC均没有在指定时间内完成训练任务,最后会卡在某个角度的训练上。对比两个实验,发现探测范围限制对实验结果的影响要强于噪声对结果的影响。推测这和SAC的算法原理有关,因为SAC算法对于噪声有比较好的健壮性。
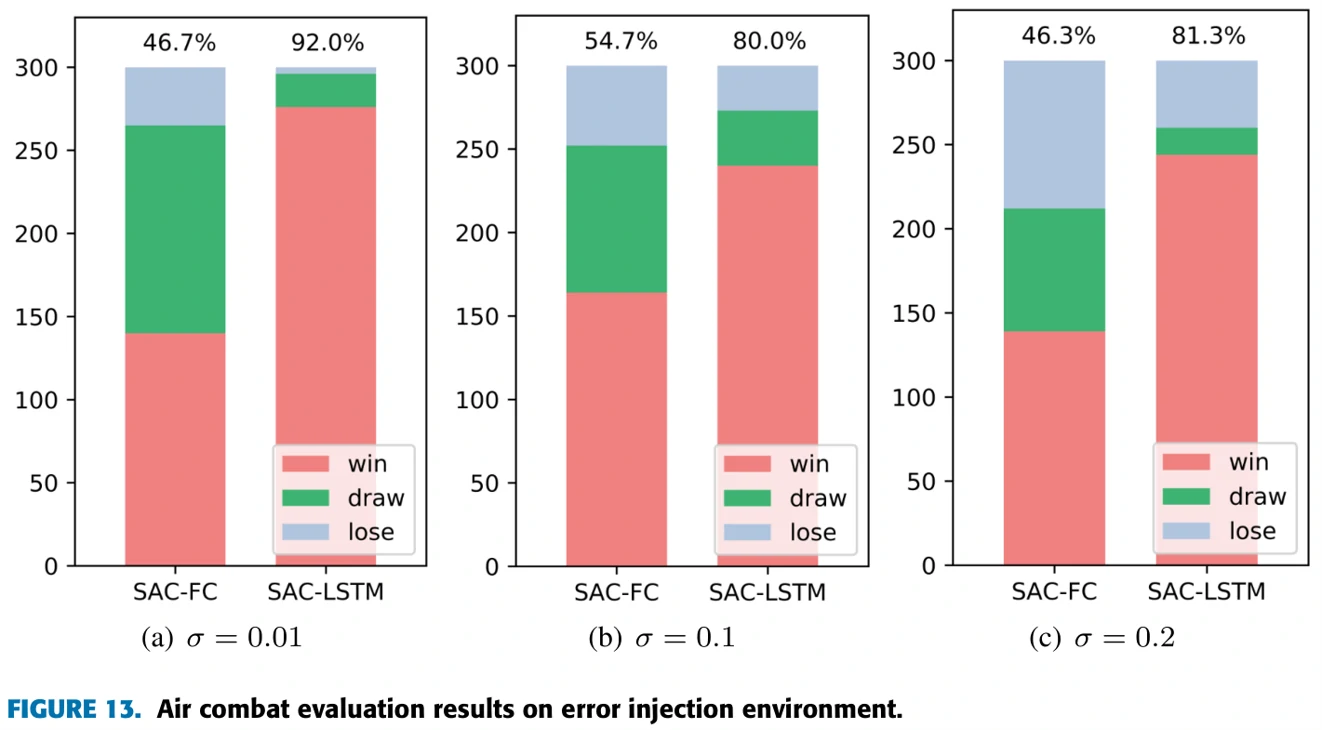
图13显示胜率情况。SAC-LSTM平均胜率是84.4%,SAC-FC平均胜率是49.2%。
3)Curriculum Learning Effect Evaluation
验证课程学习方法是否能在训练过程中提高效率和智能体表现。固定POMDP环境,探测范围5km,噪声0.01。
SAC-LSTM用上文提到的课程学习方法训练,SAC-LSTM-no-curriculum在中立态势下训练,两机初始位置随机。
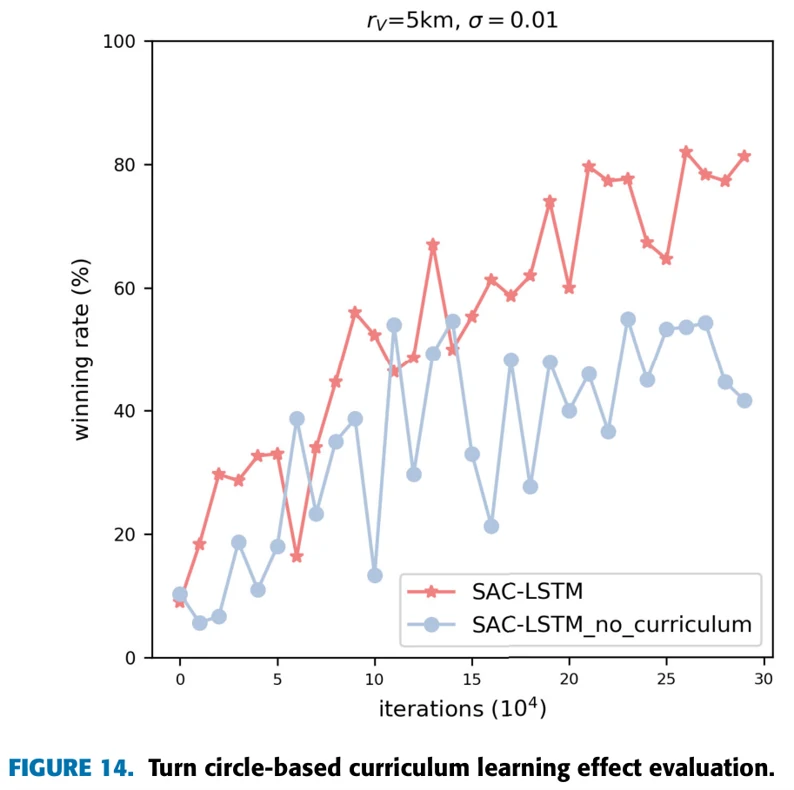
图14展示两种智能体与固定策略飞机作战的胜率,随训练过程的变化。SAC-LSTM胜率提升比较快,胜率高于SAC-LSTM-no-curriculum。这说明课程学习在近距空战的训练中起到了作用。
4)Maneuver Analysis
通过分析训练过程产生的记录,观察飞机在训练过程中是否采取了可以用在实战中的机动决策。
近距空战可用的机动:High/Low Yo-Yo, Scissors, Lag/Barrel Roll, Defensive Spiral等。
- High Yo-Yo:可用于本机优势,本机速度更快的情况,用于处理overshooting问题。
- Low Yo-Yo:本机优势,敌机离自己较远时可用。下降高度来提速,逐渐减少转弯半径,咬住敌机尾巴。
- Scissors:通过旋转来导致或预防overshoot
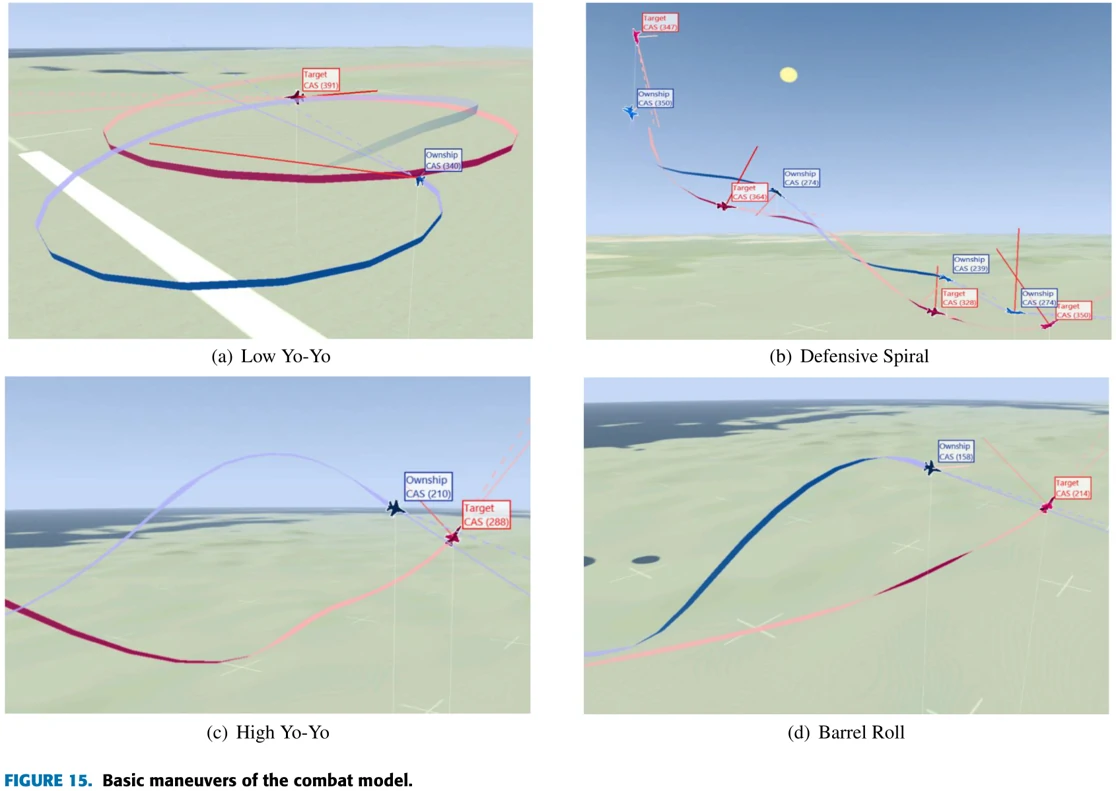
图15展示训练过程中发现的集中机动。蓝机是智能体操控的飞机,红机采用固定策略的敌机。
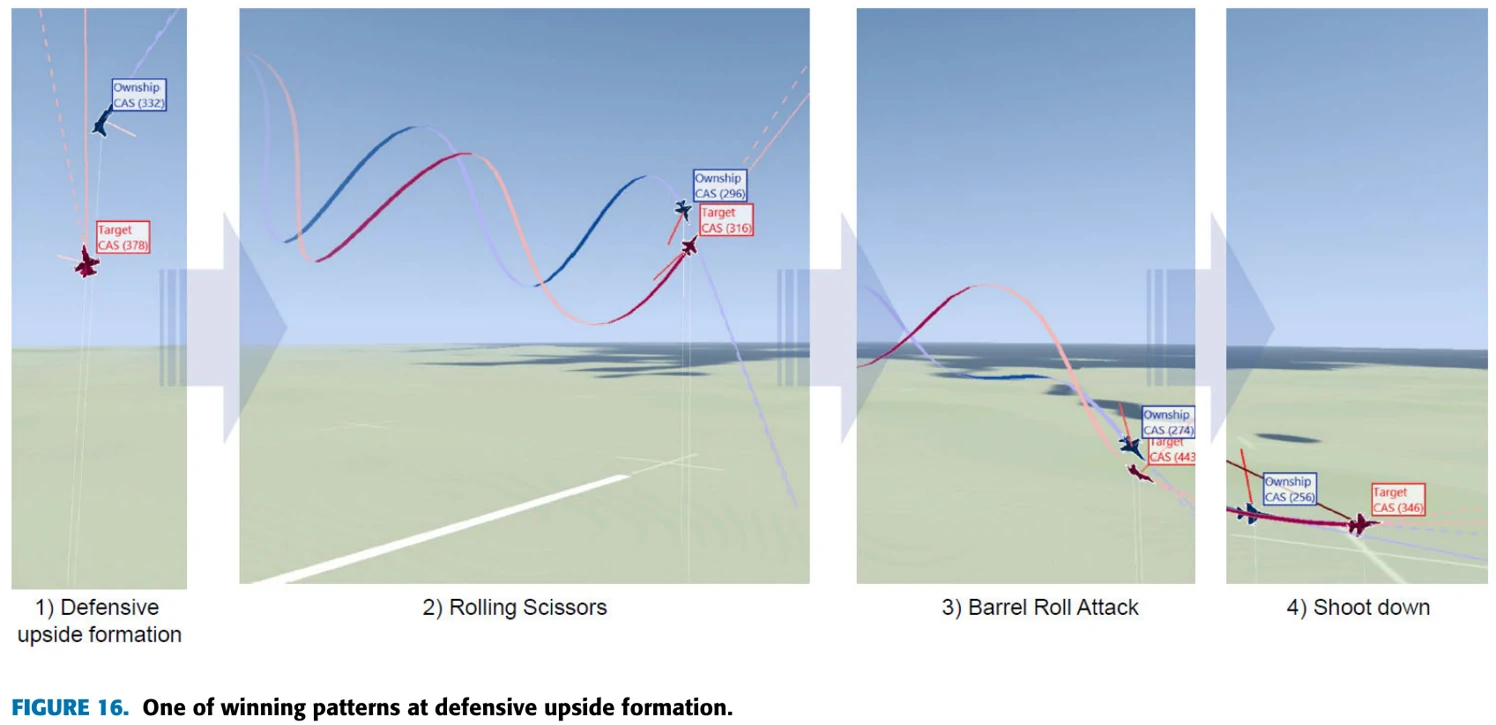
图16展示了本机在自身劣势态势下,赢下对局的过程中采用的一些机动。本机用Rolling Scissors引起了敌机的overshoot,然后用Barrel Roll Attack进攻。
总结
从全文来看,作者提出一种在具有真实限制与误差的作战环境下,开发RL模型的框架,包括一个只有部分可观测信息的环境、用作训练的SAC算法(包含一种带有LSTM的网络)、引入课程学习的训练过程。
扩展阅读
(本节主编:同学B)