论文阅读:《Maneuver-Conditioned Decision Transformer for Tactical in-Flight Decision-Making》
本文记录笔者近期阅读的一篇论文所产生的部分记录。论文主题是用一个和Transformer有关的离线强化学习框架来解决空战决策问题。
有些涉及原理的部分(比如DT的细节),因为不太懂,所以没怎么写。以后用到时再补充吧。
Intro
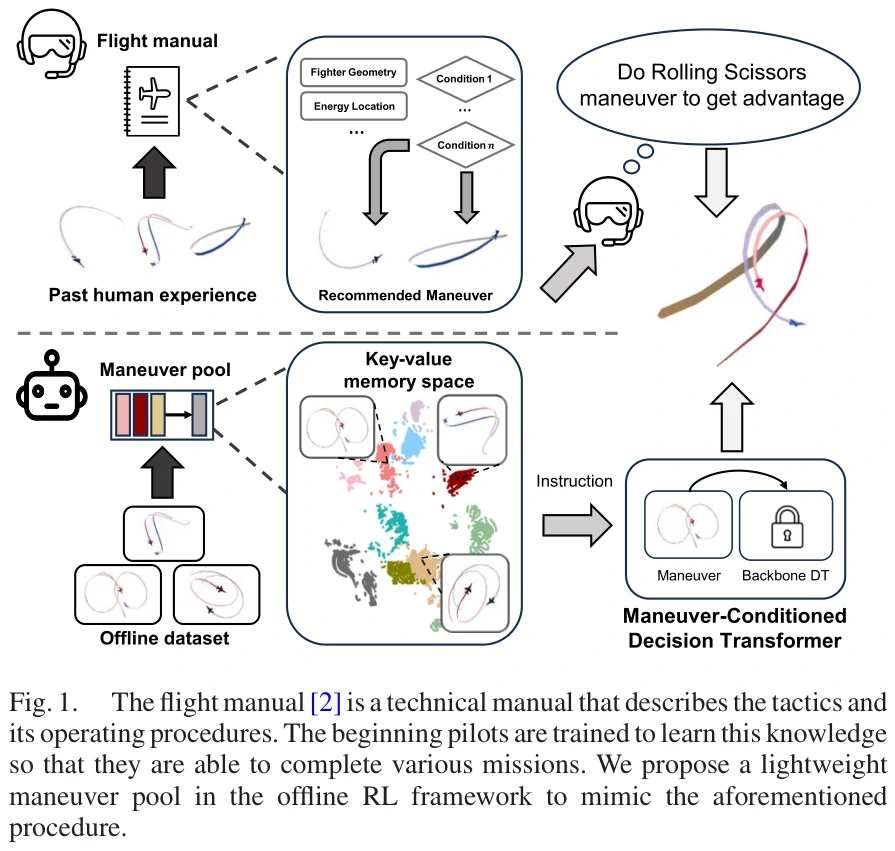
6自由度、近距空战 (within visual range, WVR)、离线强化学习
- 先收集控制器、人类、在线强化学习算法和模拟器交互的数据,做了一个训练集。
- 用一个transformer做决策:maneuver-conditioned decision transformer (M-DT)
- 在拟真环境下测试M-DT的有效性和灵活性。
离线强化学习相比在线有哪些好处?
- 不依赖主动数据收集,与环境交互成本不高,也不会有太大风险
- 更好利用先前收集的轨迹的静态数据做训练
相关工作
目前没看到有啥好写的。
前置知识
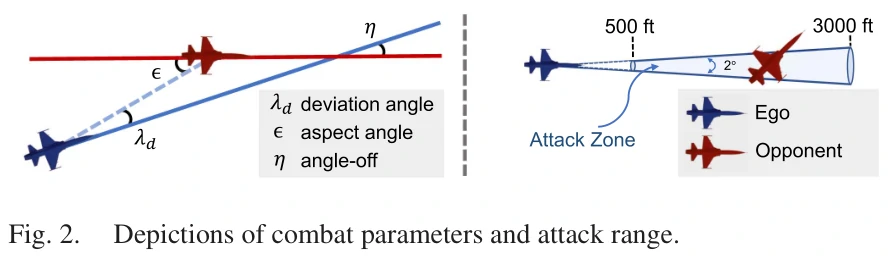
空战环境
规定了交战距离、状态空间、动作空间等。
Decision Transformer
把离线RL看作一个序列建模问题。
论文方法
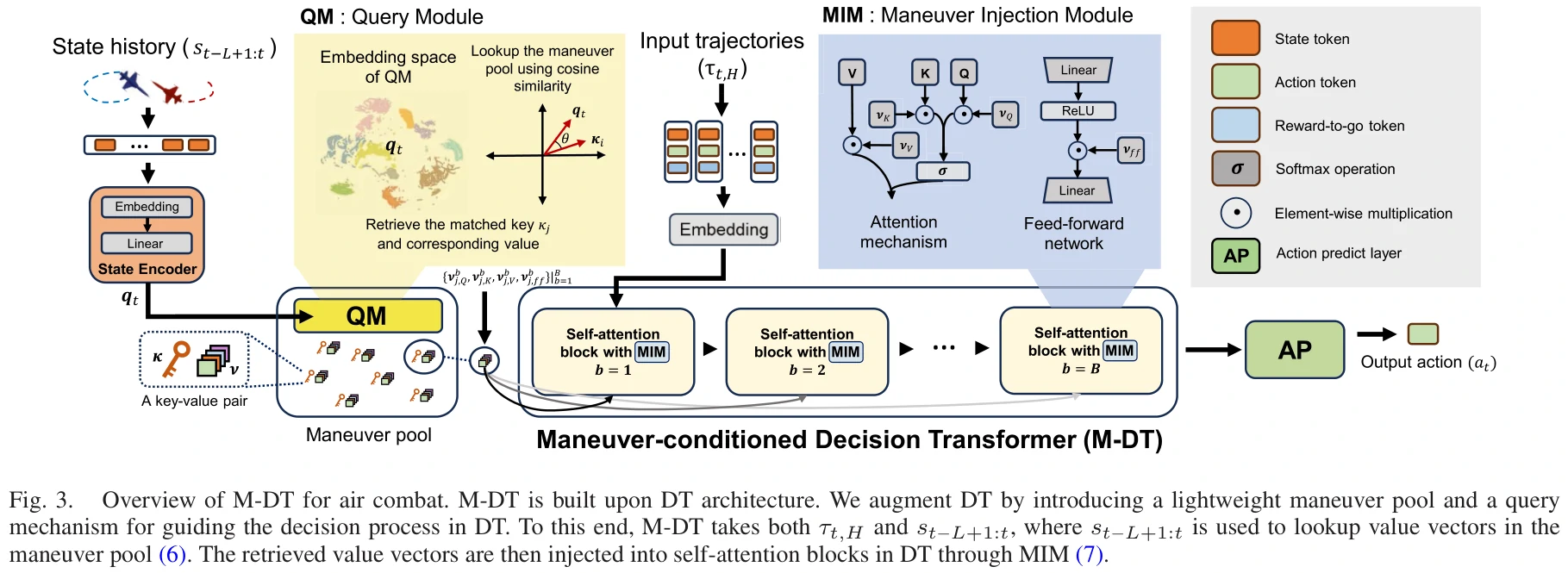
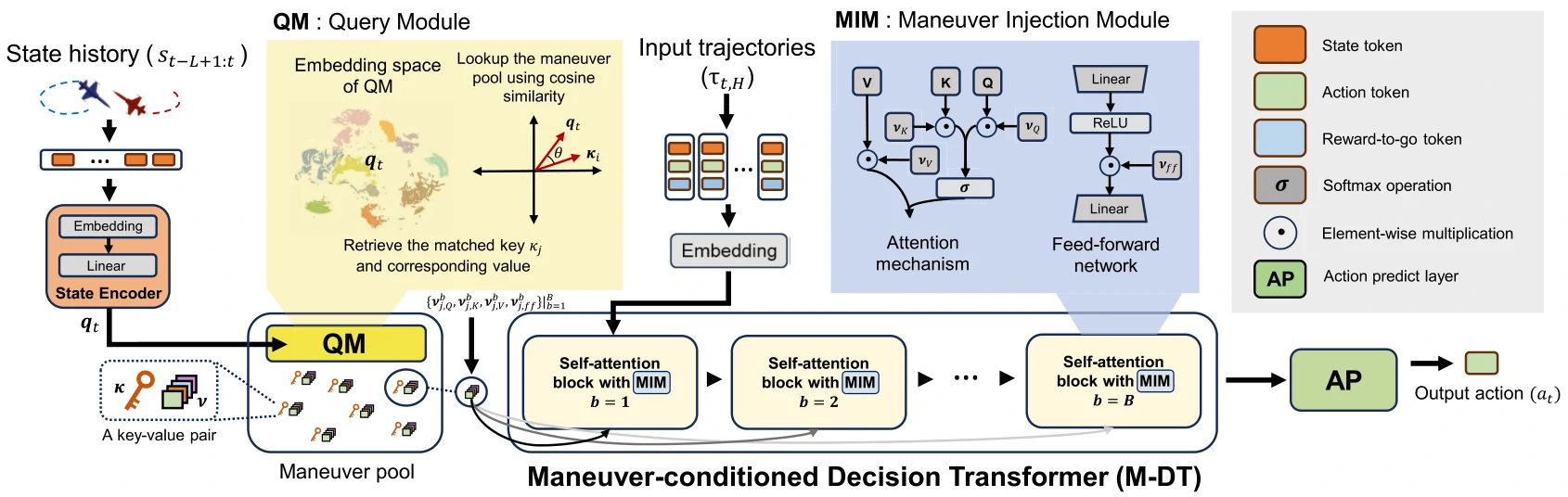
M-DT主要由查询模块(QM)、机动池、机动注入模块(MIM)和DT,4个组件组成。
机动池包含一群键值对,记录了不同的原型机动模式。用键来查询机动,同时也隐式地对机动进行了分类。
训练M-DT是端到端的,不需要预训练。使用MSE、池集中化损失和池多样化损失训练M-DT。
实验
实验方案
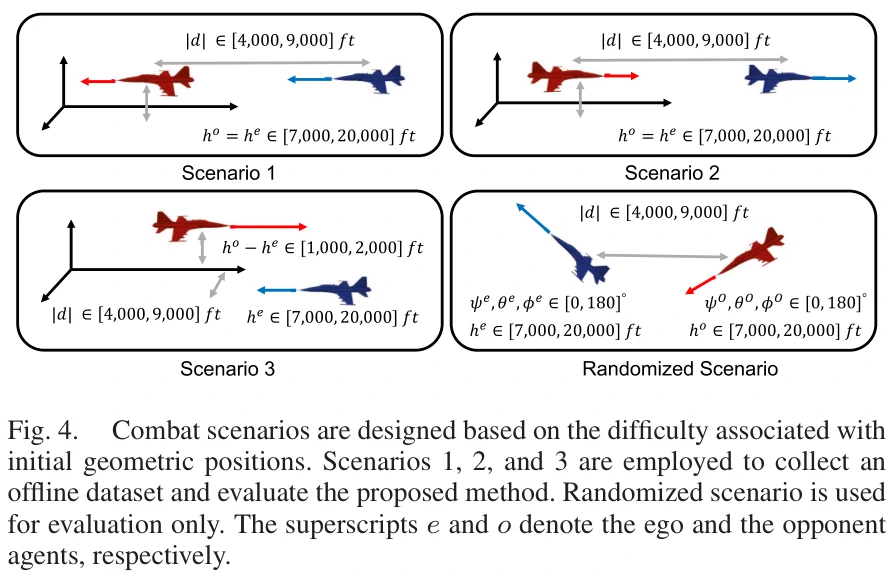

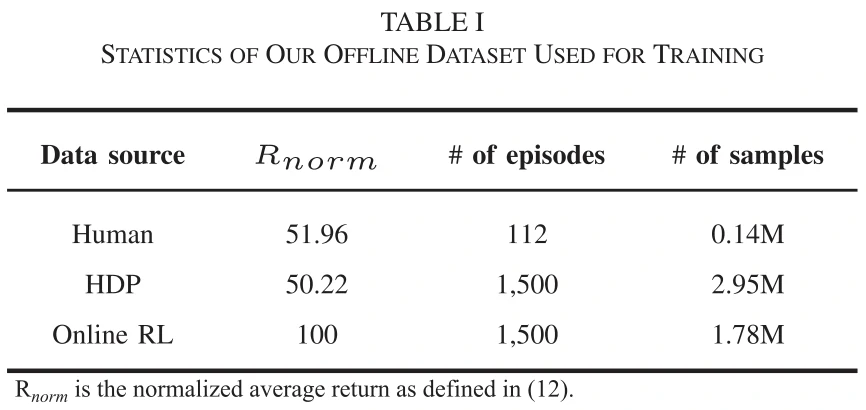
收集离线数据集。
数据收集:
- 场景1,相同高度,红机角度劣势
- 场景2,相同高度,红机角度优势
- 场景3,角度均势,红机高度优势
方法评估:
- 场景123
- 场景4,随机初始姿态角,4000到9000英尺,随机水平距离,7000到20000英尺随机海拔
收集方式:
- 人为操纵杆控制
- 手动设计、基于行为树等算法
- 在线强化学习方法,使用SAC+课程学习
消融实验
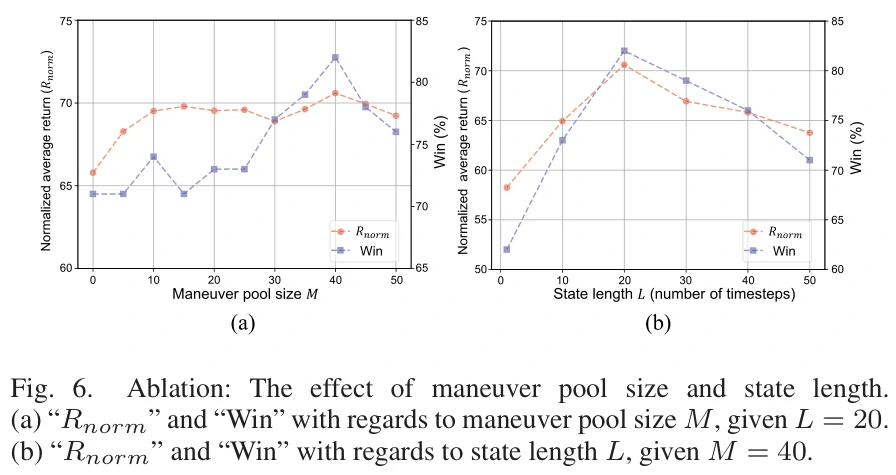
M:机动池大小,决定空战中存在的机动总数。
L:状态长度,决定用于提取特定机动信息的时间步数。
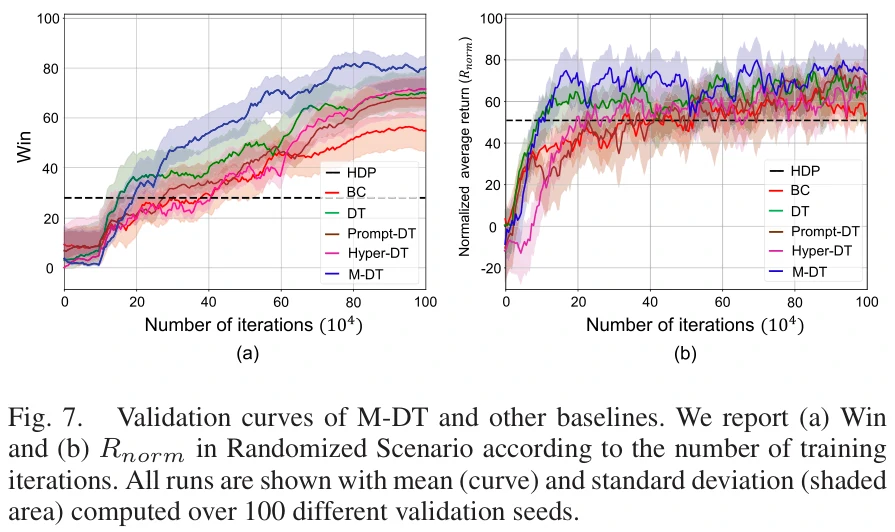
图6(a)表明增加M对性能有积极影响;图6(b)表明L为20个时间步时表现最佳(最佳动作是用2秒的信息提取的)。
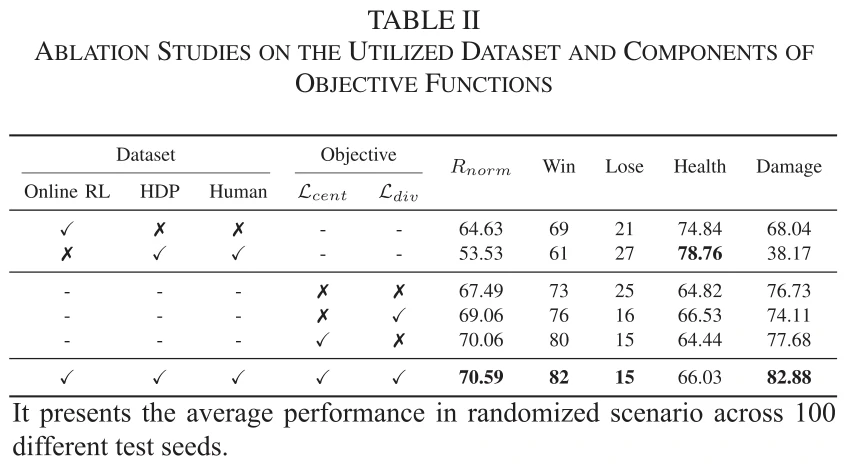
表2第1/2/6行对比,表明,与单独的专家数据集相比,用完整数据集的性能更高。
表2第3-6行对比,表明,应用集中损失
与基线对比
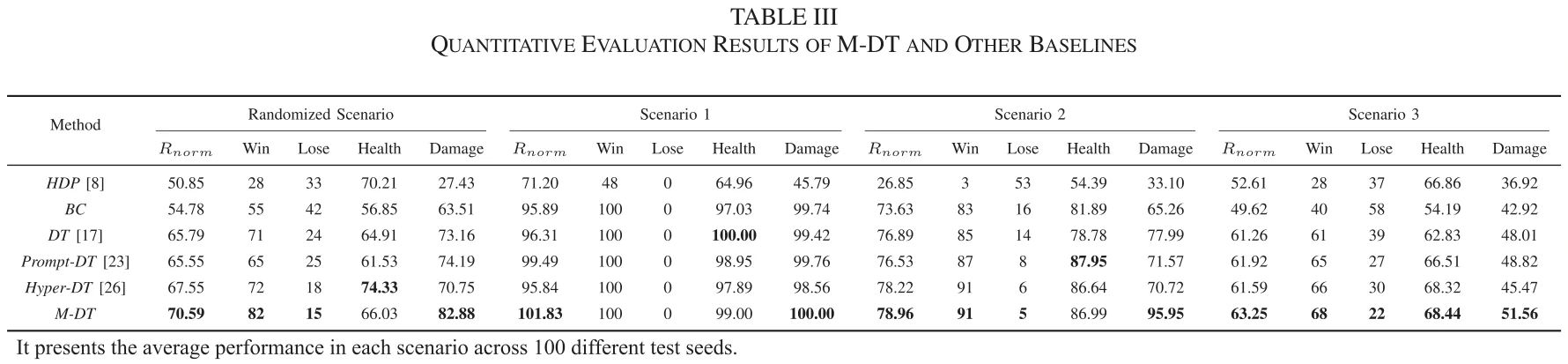
表3比较了M-DT和其他离线RL算法。
Prompt-DT和Hyper-DT是DT的变体,通过将专家策略或演示的特定信息集成到DT中。在场景1到3中,它们表现出比DT更好的性能,但在随机场景中提升较少。
M-DT不是直接使用专家演示,而是学习特定于机动的功能原型,并与DT中的自注意力块深度交互,在各种场景中的表现更好。
机动分析
由M-DT产生的特定场景下的机动
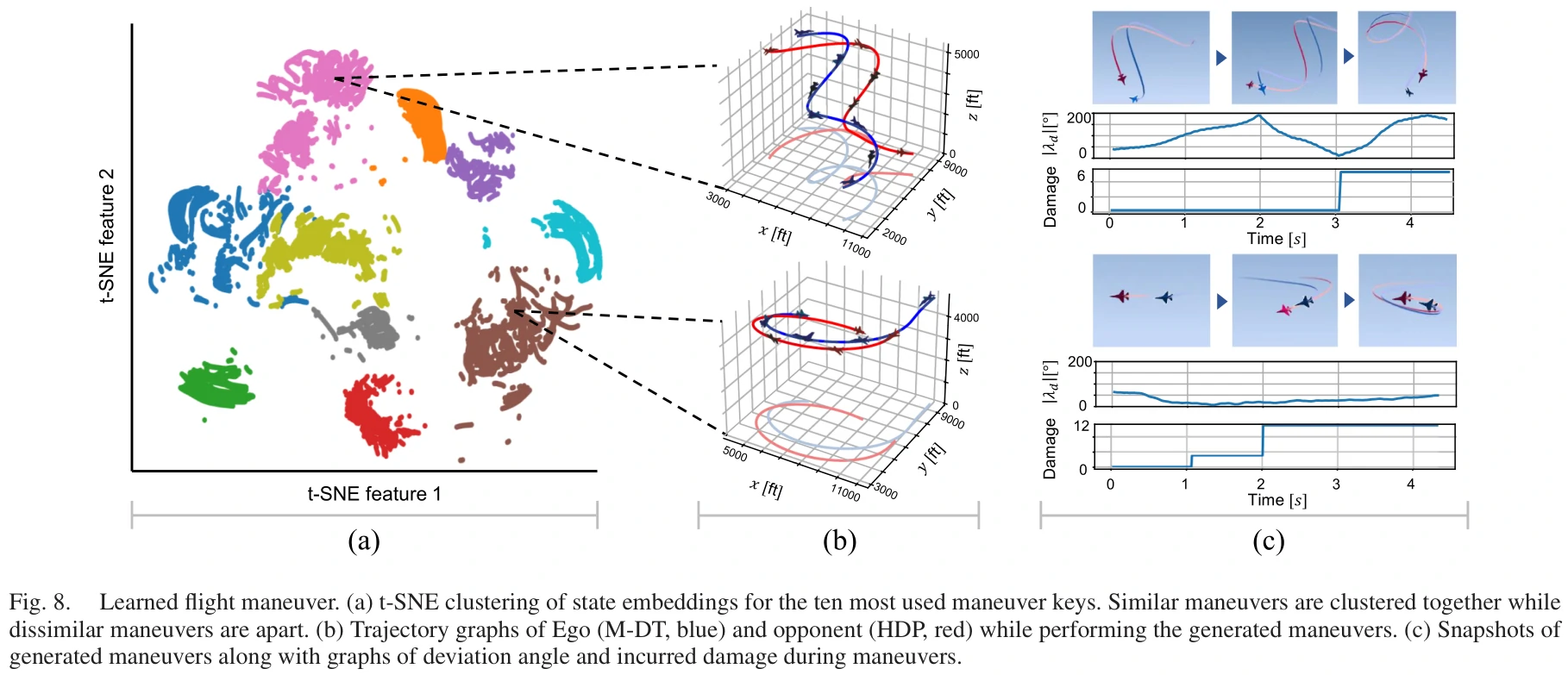
从随机场景中的10个episode中,对状态嵌入进行采样,并使用t-SNE将它们聚类为两个嵌入空间维度。
- 图8(a)表明,状态嵌入为相应的键正确地聚集,且每个键都被适当地分离。
- 图8(b)将图8(a)中分别映射的机动轨迹与基本战斗机机动(BFM)进行了比较。
- 图8(c)展示了轨迹过程中角度优势和伤害优势的变化情况。
无在线RL数据的M-DT
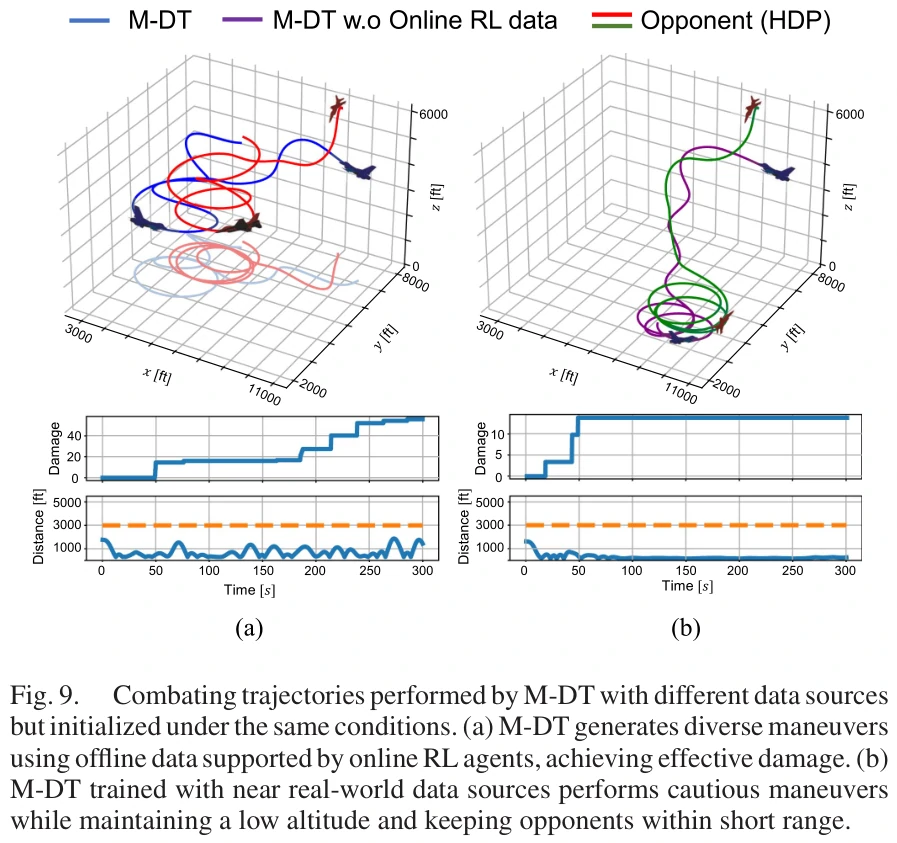
讨论
老板和前辈讨论:
好像这论文没提供代码和离线数据集?
如果离线数据集能拿到的话,就可以用来训练其他的算法。
Q:在线强化学习相比离线强化学习,可能学到一些崭新的、之前没有的决策,离线强化学习能做到吗?
A:一般学不到比之前已有决策更好的决策,但是可以通过拟合获得和专家接近的知识。
Q:如果离线数据集中掺入了一些很糟糕的决策,会出现什么现象、后果?
A:把比较差的数据剔除出去,是目前离线强化学习的一个课题。
离线强化学习,专家策略不好找数据集。
如果能做出来,还是挺有新意的。